Snap es un sistema de empaquetado y distribución de software desarrollado por Canonical, la empresa detrás de Ubuntu. Su propósito es simplificar la instalación de aplicaciones en Linux y hacer que funcionen igual en cualquier distribución.
¿Qué problema resuelve Snap?
Tradicionalmente, cada distribución Linux usa su propio sistema de paquetes:
Ubuntu/Debian usan .deb
Fedora usa .rpm
Arch usa pacman
Eso obliga a los desarrolladores a crear versiones distintas del mismo programa para cada sistema. Snap elimina esa fragmentación: crea un paquete único y autocontenido, que funciona en cualquier distribución compatible con snapd.
¿Qué contiene un paquete snap?
Un snap no solo trae el programa principal, sino todas sus dependencias: bibliotecas, binarios y configuraciones necesarias para ejecutarlo. En cierto modo, se comporta como un mini contenedor, aunque no es Docker: no usa el kernel aislado, pero sí espacios de nombres (namespaces) para mantenerlo separado del sistema principal.
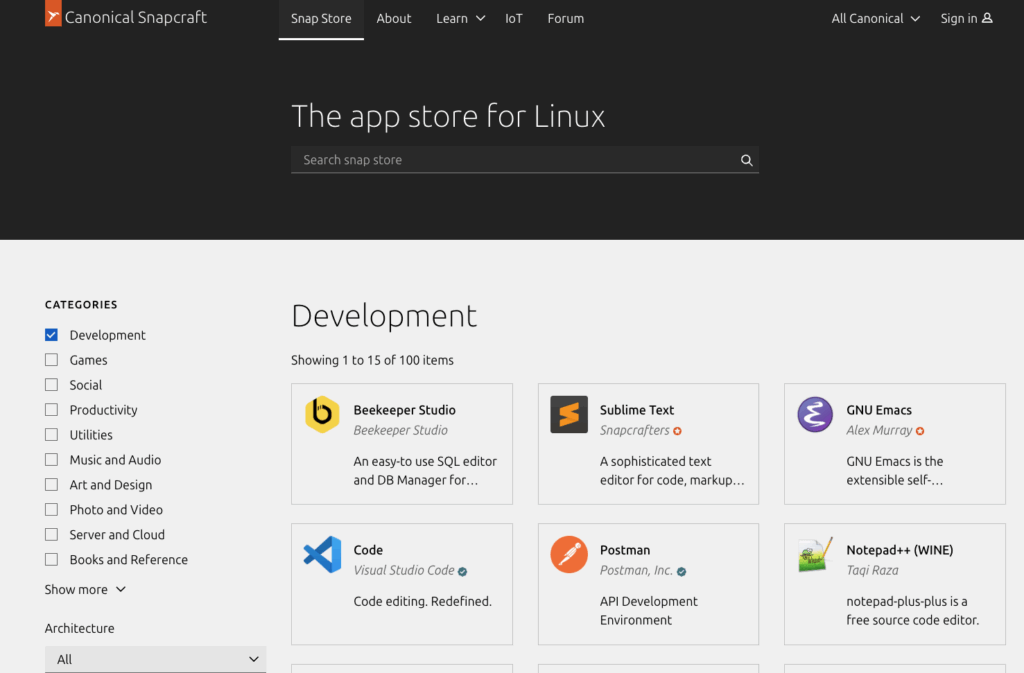
¿Cómo se instala y usa?
Primero se instala el servicio que gestiona los snaps:
sudo apt install snapd
Luego puedes instalar aplicaciones desde el Snap Store:
Ahí verás todas las aplicaciones disponibles, clasificadas por categorías:
Servidor (Nextcloud, Wekan, Mosquitto, etc.)
Desarrollo (VS Code, Postman, Node, etc.)
Productividad (LibreOffice, Slack, etc.)
Multimedia (OBS Studio, Spotify, VLC, etc.)
Cada ficha tiene los comandos exactos para instalarla en Ubuntu u otras distribuciones compatibles.
Desde la terminal
Una vez instalado snapd, puedes explorar el catálogo directamente.
Buscar una aplicación concreta:
snap search wekan
O algo más genérico:
snap search editor
snap search server
snap search database
Te mostrará una tabla con:
Name Version Publisher Notes Summary wekan 7.15 x2visio✓ - The open-source Trello-like kanban
Ver las aplicaciones ya instaladas:
snap list
Información detallada de una app:
snap info wekan
TAREA
Inicia una maquina virtual Ubuntu Server (Puedes crear una nueva o partir de una clonación que tengas con un server «Limpio»). Instala en el servidor Wekan utilizando Snap
Header always set X-Content-Type-Options "nosniff" Header always set X-Frame-Options "SAMEORIGIN" Header always set Referrer-Policy "strict-origin-when-cross-origin"
HSTS (solo si vais a usar HTTPS siempre; en lab puede dar guerra si cambiáis):
Header always set Strict-Transport-Security "max-age=86400"
7) Logs y troubleshooting (lo que siempre salva vidas)
Apache no escucha en 443: revisa que ssl esté activo y que el sitio https-lab.conf esté habilitado. sudo a2query -m ssl sudo a2query -s https-lab sudo apache2ctl -S
Certificado no coincide (CN mal): recrea el cert con CN correcto.
Permisos: que Apache pueda leer el .crt y .key (en /etc/apache2/ssl suele ir bien con root y lectura adecuada; si te pasas bloqueando, falla).
El objetivo de esta práctica es diseñar, instalar, configurar y documentar una pequeña infraestructura virtual compuesta por varias máquinas Ubuntu Server conectadas en red local.
Cada máquina deberá tener una función concreta dentro del sistema y deberá relacionarse con las demás. El alumno tendrá que demostrar conocimientos de instalación de sistemas operativos, virtualización, configuración de red, instalación de servicios, administración del sistema, seguridad, automatización y documentación técnica.
Requisitos del proyecto
Debes crear al menos 3 máquinas virtuales Ubuntu Server con IP fija:
un servidor web
un servidor de base de datos
un servidor de administración o mantenimiento
Debes realizar, como mínimo, las siguientes tareas
instalar Ubuntu Server en las máquinas virtuales
configurar la red local y las IP fijas
instalar y configurar Apache en el servidor web
instalar y configurar MySQL o MariaDB en el servidor de base de datos
comprobar la comunicación entre el servidor web y el de base de datos
administrar servicios con systemctl
consultar registros con journalctl
aplicar reglas básicas de seguridad con ufw
crear scripts Bash de mantenimiento
automatizar tareas con cron
documentar todo el proceso en un README técnico
La entrega deberá incluir
README.md principal
capturas o evidencias organizadas por apartados
scripts utilizados
archivos de configuración relevantes
comprobaciones finales de funcionamiento
Importante
No se valorará únicamente que “funcione”, sino que el trabajo esté bien explicado, justificado y documentado. Cada apartado debe mostrar comandos, explicación de su uso, resultado obtenido y evidencias del funcionamiento.
Objetivos didácticos
Con este proyecto el alumno deberá demostrar que sabe:
Crear y configurar máquinas virtuales
Instalar Ubuntu Server
Asignar IP fija a cada máquina
Configurar red local entre máquinas
Instalar y administrar servicios como:
Apache o Nginx
MySQL o MariaDB
Gestionar servicios con systemctl
Consultar registros con journalctl
Configurar reglas básicas de seguridad con ufw
Crear scripts Bash para tareas de mantenimiento
Programar tareas automáticas con cron
Verificar conectividad y dependencias entre sistemas
Para que el proyecto tenga sentido, conviene que las máquinas tengan relación entre sí.
Máquina 1: servidor web
Nombre: web01
IP fija: 192.168.1.10
Servicios:
Apache2
Página web de prueba
Función:
Servir una web que muestre información del sistema
Conectarse a la base de datos remota para validar que existe comunicación
Máquina 2: servidor de base de datos
Nombre: db01
IP fija: 192.168.1.20
Servicios:
MySQL Server o MariaDB
Función:
Alojar una base de datos
Permitir conexión desde web01
Tener usuarios y permisos configurados
Máquina 3: servidor de administración / monitorización básica
Nombre: admin01
IP fija: 192.168.1.30
Servicios y funciones:
Acceso por SSH a las otras máquinas
Scripts de mantenimiento
Tareas programadas por cron
Recolección de información del sistema
Función:
Ejecutar scripts
Hacer comprobaciones de red
Centralizar tareas administrativas básicas
Relación de dependencia entre máquinas
web01 depende de db01 porque debe conectarse a la base de datos remota
admin01 depende de web01 y db01 porque debe administrarlas o comprobar su estado
todas deben estar en la misma red local virtual y responder entre sí
graph TD
A[Entorno de virtualización] --> B[Red local virtual 192.168.50.0/24]
B --> C[web01<br>192.168.50.10<br>Ubuntu Server<br>Apache]
B --> D[db01<br>192.168.50.20<br>Ubuntu Server<br>MySQL / MariaDB]
B --> E[admin01<br>192.168.50.30<br>Ubuntu Server<br>SSH / Scripts / Cron]
C -->|Consulta remota| D
E -->|Administración y comprobación| C
E -->|Administración y comprobación| D
C --> F[Servicio web activo]
D --> G[Base de datos activa]
E --> H[Scripts de mantenimiento]
E --> I[Tareas automáticas con cron]
E --> J[Comprobación de logs y servicios]
C --> K[UFW]
D --> K
E --> K
F --> L[Documentación README]
G --> L
H --> L
I --> L
J --> L
K --> L
Requisitos mínimos del proyecto
El alumno deberá cumplir, como mínimo, lo siguiente:
Virtualización
Crear 3 máquinas virtuales
Asignar recursos coherentes
Instalar Ubuntu Server en todas
Red
Configurar una red local virtual
Asignar IP fija a cada máquina
Verificar conectividad con ping
Servicios
Instalar Apache en web01
Instalar MySQL o MariaDB en db01
Comprobar que el servicio web funciona desde navegador o con curl
Comprobar que la base de datos acepta conexiones
Administración
Usar comandos de terminal durante todo el proyecto
Gestionar servicios con systemctl
Consultar logs con journalctl
Seguridad
Activar y configurar ufw
Permitir solo los puertos necesarios
Explicar qué puertos se abren y por qué
Automatización
Crear al menos 2 scripts Bash
Programar al menos 2 tareas con cron
Fases del proyecto
flowchart TD
A[Planificación] --> B[Virtualización]
B --> C[Instalación de sistemas]
C --> D[Configuración de red]
D --> E[Conectividad]
E --> F[Servidor web]
E --> G[Servidor de base de datos]
F --> H[Comunicación entre servicios]
G --> H
H --> I[Administración de servicios]
I --> J[Revisión de logs]
J --> K[Seguridad con UFW]
K --> L[Scripts de mantenimiento]
L --> M[Tareas automáticas con cron]
M --> N[Pruebas finales]
N --> O[Documentación README y evidencias]
Fase 1. Creación de la infraestructura virtual
Tareas
Instalar el software de virtualización
VirtualBox, VMware o similar
Crear 3 máquinas virtuales
Asignar nombre a cada una
Instalar Ubuntu Server en cada una
Evidencias obligatorias
Captura del software de virtualización mostrando las 3 máquinas
Captura del proceso de instalación o del sistema ya instalado
Tabla con nombre, RAM, disco y función de cada VM
Qué debe explicar en el README
Qué programa de virtualización ha utilizado
Qué recursos ha asignado a cada VM
Por qué ha organizado así la infraestructura
Fase 2. Configuración de red
Tareas
Configurar red local entre las máquinas
Asignar IP fija a cada sistema
Comprobar conectividad
Ejemplo de tabla de red
Máquina
IP
Máscara
Puerta de enlace
Función
web01
192.168.50.10
255.255.255.0
192.168.50.1 o vacía si no aplica
Web
db01
192.168.50.20
255.255.255.0
192.168.50.1 o vacía si no aplica
BD
admin01
192.168.50.30
255.255.255.0
192.168.50.1 o vacía si no aplica
Administración
Comprobaciones que deben hacer
ip a
hostnamectl
ping entre máquinas
Evidencias obligatorias
Archivo de configuración de red o capturas del mismo
Resultado de ip a
Resultado de pings exitosos entre las máquinas
Qué debe explicar en el README
Cómo ha configurado la IP fija
Qué problemas encontró
Cómo comprobó que la red funciona
Fase 3. Instalación y configuración del servidor web
Tareas
En web01:
Instalar Apache2
Arrancar y habilitar el servicio
Crear una página de prueba
Comprobar acceso desde la propia máquina y desde otra
Qué riesgos existirían si se abrieran más puertos de la cuenta
Fase 8. Scripts de mantenimiento
Tareas
Crear al menos dos scripts Bash.
Script 1: comprobación del sistema
Debe mostrar:
hostname
IP
uso de disco
uso de memoria
fecha
estado de un servicio
Script 2: copia de logs o informe de mantenimiento
Debe:
crear una carpeta de copias o informes
guardar fecha y hora
copiar un log o generar un resumen del sistema a un archivo
Ejemplo de ideas
check_web.sh
backup_logs.sh
estado_sistema.sh
Evidencias obligatorias
Código de los scripts
Captura de ejecución
Explicación línea por línea o por bloques
Qué debe explicar en el README
Para qué sirve cada script
Cómo se ejecuta
Qué permisos necesita
Qué salida genera
Fase 9. Automatización con cron
Tareas
Programar al menos dos tareas automáticas:
una para ejecutar un script de mantenimiento
otra para generar un informe o copia
Comandos esperados
crontab -e crontab -l
Evidencias obligatorias
Captura de crontab -l
Captura o prueba del archivo generado por cron
Explicación del formato del cron
Qué debe explicar en el README
Qué tarea automatizó
Cada cuánto se ejecuta
Cómo verificó que realmente se ejecutó
Plantilla de README
Puedes darles esta estructura para obligarles a documentar bien.
# Proyecto: infraestructura virtualizada con Ubuntu Server
## 1. Datos del alumno
- Nombre:
- Curso:
- Módulo:
- Fecha:
## 2. Introducción
Explica brevemente en qué consiste el proyecto y cuáles son sus objetivos.
## 3. Diseño de la infraestructura
### 3.1 Máquinas virtuales creadas
| Máquina | Función | IP | Sistema operativo |
|---|---|---|---|
### 3.2 Relación entre máquinas
Explica cómo se comunican y de qué depende cada una.
## 4. Instalación de Ubuntu Server
Describe el proceso de creación e instalación de cada máquina virtual.
### Evidencias
- Capturas
- Configuración asignada
- Observaciones
## 5. Configuración de red
Explica cómo configuraste la IP fija en cada máquina.
### Comandos utilizados
~~~bash
ip a
ping
Estructura de entrega recomendada
Puedes utilizar esta estructura para la documentación:
Explica la instalación del servidor de base de datos en db01.
Comandos utilizados
sudo apt install mysql-server -y
Verificación
Explica cómo comprobaste que funciona.
Comunicación entre servicios
Explica cómo el servidor web accede al servidor de base de datos.
Pruebas realizadas
ping
conexión remota
consulta SQL
Gestión de servicios con systemctl
Explica qué comandos usaste para iniciar, parar, reiniciar y habilitar servicios.
Consulta de logs con journalctl
Indica qué logs revisaste y qué información encontraste.
Seguridad con UFW
Explica qué reglas configuraste y por qué.
Scripts de mantenimiento
Script 1
Nombre:
Función:
Código:
Resultado:
Script 2
Nombre:
Función:
Código:
Resultado:
Tareas programadas con cron
Explica qué tareas automatizaste y cómo las comprobaste.
Comprobaciones finales
Incluye evidencias de:
IP fija
conectividad entre máquinas
Apache funcionando
MySQL funcionando
firewall activo
scripts funcionando
cron funcionando
Problemas encontrados y soluciones
Describe los errores o dificultades y cómo los resolviste.
Cómo verificar que realmente ha hecho el trabajo
Esto es clave. Hay que pedir pruebas que huelan a trabajo real y no a “copié cuatro cosas de internet y recé”. Para demostrar que es una implementación real, puedes ir incluyendo en la documentación (Donde toque) el resultado de algunso comandos.
Google Hacking es una técnica de búsqueda utilizada para encontrar información específica en los motores de búsqueda, como Google.
[!NOTA] Este tipo de búsquedas no son invasivas, ya que no hacen peticiones al servidor del objetivo, por lo que podemos utilizar estas técnicas libremente.
La Google Hacking Database (GHDB) es una colección de comandos de búsqueda de Google y técnicas de búsqueda avanzadas que se utilizan para encontrar información que puede ser útil en la realización de pruebas de penetración y en la investigación de seguridad.
La GHDB fue creada por Johnny Long, un experto en seguridad informática, y es mantenida por una comunidad de profesionales de la seguridad informática. La GHDB contiene miles de comandos de búsqueda de Google y técnicas de búsqueda avanzadas que se utilizan para encontrar información confidencial, como contraseñas, información de inicio de sesión, archivos de configuración, archivos de registro y más.
Los comandos de búsqueda de Google en la GHDB se organizan en categorías, como «Vulnerabilities», «Files containing passwords» y «Sensitive Directories». Cada comando de búsqueda viene con una descripción detallada de lo que busca y cómo se puede utilizar.
La GHDB se utiliza comúnmente en pruebas de penetración y en la investigación de seguridad para buscar información confidencial que puede ser utilizada en un ataque. Es importante tener en cuenta que la GHDB debe utilizarse con precaución y solo con el permiso del propietario del sitio web o de la red que se está probando. También es importante asegurarse de que cualquier información confidencial descubierta se informe al propietario del sitio web o a las autoridades apropiadas.
Google Dorks
Los Google Dorks son combinaciones específicas de palabras o frases que se usan para realizar búsquedas avanzadas en Google y obtener resultados que no se pueden obtener mediante una búsqueda normal.
Es importante tener en cuenta que los Google Dorks no son herramientas de hacking en sí mismas, sino una técnica para realizar búsquedas avanzadas en Google. Sin embargo, los Google Dorks pueden ser utilizados por los hackers para encontrar información sensible que puede ser utilizada en ataques posteriores. Por lo tanto, se recomienda utilizar los Google Dorks de manera responsable y con fines éticos, especialmente si se utilizan en el campo de la seguridad informática.
Operador
Descripción
Ejemplo
Explicación del ejemplo
site:
Limita resultados a un dominio específico.
site:example.com
Encuentra todas las páginas accesibles en example.com.
inurl:
Busca un término dentro de la URL.
inurl:login
Localiza páginas de inicio de sesión.
filetype:
Filtra por tipo de archivo.
filetype:pdf
Encuentra documentos PDF descargables.
intitle:
Busca un término en el título de la página.
intitle:"confidential report"
Busca documentos titulados “informe confidencial” o similares.
intext: / inbody:
Busca dentro del cuerpo del texto.
intext:"password reset"
Encuentra páginas con “restablecimiento de contraseña”.
cache:
Muestra la versión en caché de Google.
cache:example.com
Ve contenido antiguo o previo de example.com.
link:
Encuentra páginas que enlazan a otra.
link:example.com
Muestra webs que tienen enlaces hacia example.com.
related:
Encuentra páginas parecidas a otra.
related:example.com
Descubre sitios similares a example.com.
info:
Muestra información básica sobre un sitio.
info:example.com
Título, descripción y datos del sitio.
define:
Busca definiciones de una palabra.
define:phishing
Obtiene la definición de phishing.
numrange:
Busca números dentro de un rango.
site:example.com numrange:1000-2000
Busca páginas de ese dominio con números entre 1000 y 2000.
allintext:
Todas las palabras deben aparecer en el texto.
allintext:admin password reset
Localiza páginas que contienen ambas palabras.
allinurl:
Todas las palabras deben aparecer en la URL.
allinurl:admin panel
Busca URLs con “admin” y “panel”.
allintitle:
Todas las palabras deben estar en el título.
allintitle:confidential report 2023
Busca títulos con esas tres palabras.
AND
Exige que todos los términos aparezcan.
site:example.com AND (inurl:admin OR inurl:login)
Busca paneles admin o login en example.com.
OR
Acepta cualquiera de los términos.
"linux" OR "ubuntu" OR "debian"
Busca páginas que mencionen cualquiera de esos sistemas.
NOT
Excluye resultados con un término.
site:bank.com NOT inurl:login
Excluye las páginas de login.
* (comodín)
Sustituye cualquier palabra/caracter.
site:socialnetwork.com filetype:pdf user* manual
Encuentra “user guide”, “user manual”, etc.
.. (rango)
Busca valores dentro de un intervalo numérico.
site:ecommerce.com "price" 100..500
Busca productos entre 100 y 500.
"" (comillas)
Busca coincidencia exacta.
"information security policy"
Busca esa frase exacta.
- (menos)
Excluye un término concreto.
site:news.com -inurl:sports
Noticias sin resultados deportivos.
Ejemplos de uso:
Google Dork
Descripción
intitle:"Index of" password.txt
Muestra directorios que contienen archivos llamados “password.txt”.
intitle:"Index of" /admin
Muestra directorios de administración.
filetype:xls inurl:"email.xls"
Muestra listados de emails expuestos.
inurl:"login" site:example.com
Encuentra páginas de inicio de sesión en un sitio concreto.
filetype:log inurl:"password.log"
Encuentra logs cuyo nombre contiene “password”.
intitle:index.of id_rsa -id_rsa.pub
Encuentra claves privadas SSH expuestas.
site:.gov intitle:"secret" filetype:pdf
Encuentra archivos PDF gubernamentales expuestos.
intext:"Welcome to phpMyAdmin"
Encuentra instalaciones de phpMyAdmin accesibles.
inurl:/wp-content/uploads/ filetype:pdf
Busca PDFs dentro de uploads de WordPress.
intitle:"Index of" /backup
Encuentra directorios de backups accesibles.
site:example.com ext:sql
Busca bases de datos SQL en ese dominio.
intitle:"index of" "database.sql"
Busca archivos SQL expuestos.
intitle:"SQL Injection" site:example.com
Encuentra páginas del sitio que mencionan SQL Injection.
Muestra el directorio actual del servidor (grave exposición).
intitle:"index of" intext:web.config
Directorios indexados con web.config.
filetype:reg reg HKEY_CURRENT_USER username
Busca archivos de registro que contengan “username”.
inurl:"ViewerFrame?Mode="
Encuentra cámaras accesibles por ese visor.
intext:"powered by vBulletin"
Encuentra webs que usan vBulletin.
intitle:"index of" inurl:ftp
FTPs accesibles de forma pública.
intitle:"index of" "WhatsAppDB.csv"
Directorios con bases de datos de WhatsApp expuestas.
filetype:env intext:APP_ENV
Busca archivos .env con info sensible.
inurl:"/phpinfo.php"
Encuentra páginas phpinfo expuestas.
intitle:"index of" intext:sftp-config.json
Directorios con configuraciones SFTP.
A continuación se muestran algunos ejemplos comunes de Google Dorks; para obtener más ejemplos, consulte la Google Hacking Database:
Encontrar páginas de inicio de sesión:
site:example.com inurl:login
site:example.com (inurl:login OR inurl:admin)
Identificar de archivos expuestos:
site:example.com filetype:pdf
site:example.com (filetype:xls OR filetype:docx)
Descubrir archivos de configuración:
site:example.com inurl:config.php
site:example.com (ext:conf OR ext:cnf)(busca extensiones comúnmente utilizadas para archivos de configuración)
Localizar copias de seguridad de bases de datos:
site:example.com inurl:backup
site:example.com filetype:sql
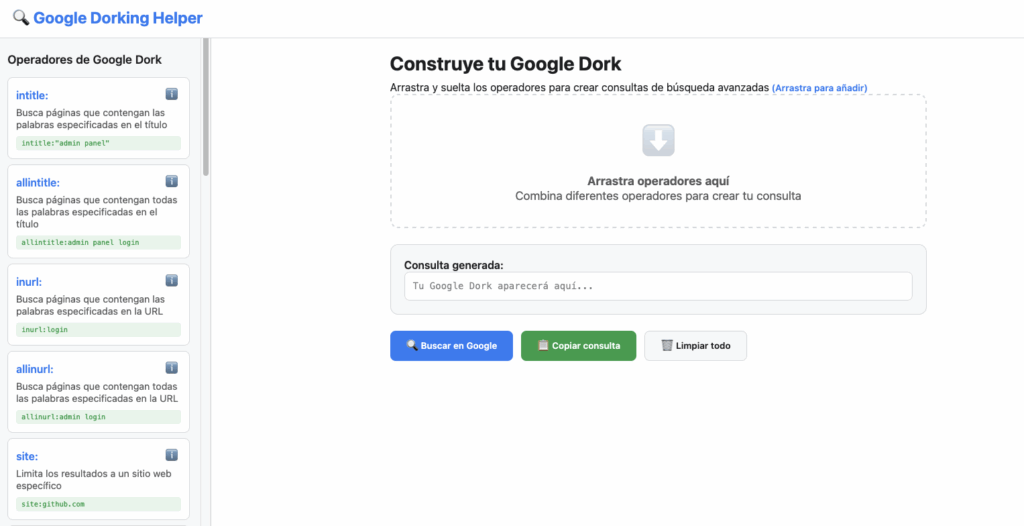
Automatización: Google Dorking Helper
Podemos automatizar la generación de Google Dorks con herramientas cómo Google Dorking Helper, que nos permite arrastrar operadores para ir construyendo nuestro dork. Una vez que lo hemos generado podemos darle directamente a «Buscar en Google» para abrirlo en el navegador.
CASO DE USO: Detectando archivos expuestos en un dominio con Google Dorks
Imagina que quieres comprobar example.com (o cualquier dominio propio de prácticas) expone algún archivo de configuración, backups o bases de datos de forma accidental.
1. Entramos en GoogleDorks (la web recopilatoria)
Hay varias webs que recopilan dorks ya probados, como:
Exploit-DB Google Hacking Database (GHDB)
googledorks.com
publicdorks repos en GitHub
Las usan solo como referencia, nunca para atacar sistemas reales.
2. Elegimos un dork útil para auditoría
Por ejemplo, un clásico para detectar bases de datos expuestas:
site:example.com ext:sql
Este dork busca archivos .sql accesibles desde el navegador.
3. Lo probamos en Google
En un entorno de práctica (por ejemplo, un dominio controlado por el aula), lo que vemos es algo así:
/backup/database.sql
/db/export_2023.sql
/old/backup.sql
Si Google muestra entradas similares, quiere decir que los archivos son accesibles públicamente y están indexados. Eso convierte una simple curiosidad en un aviso rojo.
4. Interpretamos el resultado
Les explicas a los alumnos:
Si Google lo indexa, quiere decir que el servidor lo publica sin restricciones
Esto no es hacking activo; es lectura pública de lo que ya está expuesto.
Archivos .sql suelen contener tablas, usuarios, hashes de contraseña, etc.
Aquí entra tu guiño filosófico habitual: el buscador es como un telescopio enorme; si apuntas a una ventana con luz encendida, no estás entrando en la casa, solo ves lo que ellos dejaron abierto.
5. Propones medidas de mitigación
Esto les ayuda a cerrar el círculo mental del auditor:
Sacar carpetas de backup fuera del public_html o document root.
Configurar .htaccess o reglas en el servidor que impidan servir .sql, .env, .conf…
Quitar directorios listados (“Index of”).
Desactivar el autoindex en Apache/Nginx.
Aplicar permisos adecuados del sistema.
6. Otro ejemplo más avanzado desde GoogleDorks.com
En GoogleDorks encuentran típicamente entradas como:
intitle:"index of" /backup
Lo combinan con su dominio de pruebas:
site:example.com intitle:"index of" /backup
Resultado (en un entorno controlado): Google podría mostrar un listado de backups accesibles.
Aquí se ve el poder del dork: localizar un error de configuración sin escaneo activo ni intrusiones.
CASO DE USO: “Ventanas Abiertas en la Red”
La pantalla parpadea. No estás hackeando nada. Solo observas. Lo que Google muestra es lo que ya estaba ahí, flotando en la superficie como un mensaje en una botella. Elliot lo explica con su serenidad afilada:
«El buscador es un espejo gigante. Refleja lo que los servidores enseñan sin darse cuenta. Si sabes dónde mirar, puedes encontrar más de lo que cualquier administrador admitiría».
Elliot abre una pestaña, teclea despacio, casi ritual:
site:example.com ext:sql
Darlene levanta una ceja. «¿Ya? ¿Así de simple?»
Él asiente. «El truco nunca es forzar la cerradura; es descubrir que la puerta estaba abierta desde siempre».
La búsqueda devuelve un par de enlaces inocentes: /backup/database.sql, /old/export_2022.sql. Como si fuera normal. Como si no contuvieran medio corazón de ese servidor, latido a latido.
Darlene sonríe, ese tipo de sonrisa que solo aparece cuando ve un fallo que podría haberse evitado con dos minutos de atención. «Archivos SQL, backups… Esto es como dejar el diario íntimo abierto en medio de la calle», murmura.
Elliot continúa:
«O mira este, es más evidente»:
intitle:"index of" /backup
La pantalla muestra un directorio listado. El índice, los archivos, las fechas. Casi puedes sentir la gravedad del error. Es información pública; Google solo la ha descubierto primero.
Elliot apoya los codos en la mesa.
«Esto es Google Dorking. Nada ilegal. Buscamos lo que ya está expuesto. Como revisar los candados de tu propia casa. Y si encuentras una ventana rota, la arreglas antes de que otro la vea».
Darlene mira al techo. «La gente piensa que la seguridad es un bunker. Pero casi siempre es una persiana mal echada».
Los dos siguen navegando entre dorks como quien pasea entre sombras familiares. No hay urgencia, solo una especie de calma lúcida: la fase previa a cualquier intrusión ética, el territorio gris donde la información pública se mezcla con la negligencia.
Elliot concluye, casi en un susurro: «El buscador es el confidente más indiscreto de internet. Si le preguntas bien, te lo cuenta todo».
Buscadores alternativos y meta-buscadores
Cuando Google te cierra puertas, otros motores silenciosos dejan ventanas abiertas. No son magia negra; simplemente indexan distinto.
DuckDuckGo – Respeta privacidad y deja ver cosas que Google a veces filtra.
Shodan – El “Google del IoT”: cámaras, routers, PLCs, servidores expuestos. – Ideal para investigación forense o ética.
Censys – Similar a Shodan pero con enfoque más académico. – Perfecto para investigaciones de superficie de ataque.
Bing + Yandex – Indexan directorios de manera más permisiva en algunos casos.
Herramientas que automatizan Google Dorks (con cabeza)
No siempre quieres escribir cien consultas a mano. Estas herramientas generan, prueban y organizan dorks.
GHDB – Google Hacking Database (Exploit-DB) – La biblia. Miles de dorks clasificados por categorías (login pages, archivos sensibles, cámaras…). – La referencia imprescindible.
DorkSearch / DorkTester – Pequeñas herramientas web para probar dorks rápidamente. – Útiles para investigaciones rápidas sin automatizar demasiado.
Dork-Scanner (Python) – Frameworks que lanzan series de dorks y analizan respuestas. – Exigen ética e IP propia porque Google puede bloquearte.
Katana + Nuclei (ProjectDiscovery) – No son dorks, pero se llevan muy bien con ellos. – Puedes sacar URLs con Katana y luego comprobar hallazgos con Nuclei.
Extensiones de navegador
No subestimes las pequeñas utilidades de un clic.
Google Search Operators Helper – Te rellena operadores avanzados.
Search Diggity (BishopFox) – Conjunto de herramientas de OSINT con módulos de dorking seguro. – Muy usado en auditorías.
Herramientas OSINT que complementan Google Dorks
Porque un dork es solo un portal: después debes investigar.
theHarvester – Extrae correos, dominios, hosts desde motores de búsqueda. – Combinación perfecta con filetype:xls, pdf, txt…
FOCA – Analiza metadatos de documentos encontrados con dorks. – Joyas ocultas en PDFs y Word.
SpiderFoot – Rastrea información relacionada con dominios, subdominios y filtraciones.
Amass – Recon de subdominios. – Combinado con site: y inurl: puedes descubrir puertas laterales.
Herramientas forenses relacionadas
Cuando los dorks son parte de una investigación forense, estos compañeros hacen el resto:
Wayback Machine (Archive.org) – Para ver versiones antiguas de páginas descubiertas con dorks. – Oro puro cuando el contenido ha sido borrado.
Exiftool – Para explorar metadatos de imágenes encontradas.
Binwalk – Si encuentras firmware expuesto con un dork (sí, pasa), esta herramienta lo destripa.









![[Reto] – Infraestructura virtualizada con Ubuntu Server](https://laaventuradeaprender.com/wp-content/uploads/2026/03/9dc81aff-d57d-45b1-83e9-c70955561713.png)