404 en fetch → la ruta no coincide con el url-pattern del servlet.
El fetch devuelve HTML en vez de JSON → estás pegando a una ruta que devuelve una página, no el endpoint.
CORS: si sirves el HTML desde Tomcat y llamas al servlet en el mismo host/puerto, normalmente no hay CORS. CORS aparece si llamas a otro host/puerto distinto.
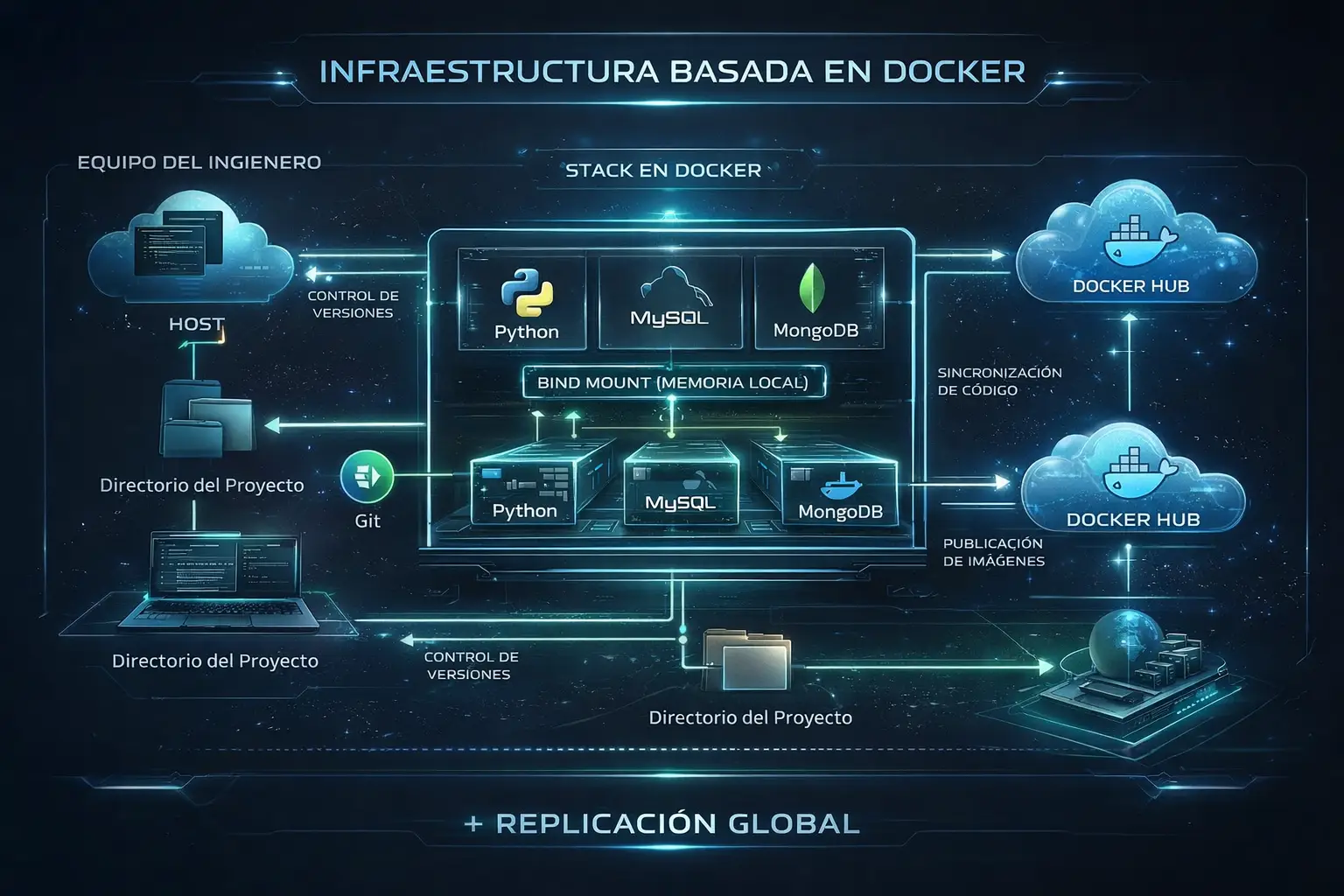
– Crear un contenedor docker de ubuntu. – Instalar python, la libreria request y de mysql – Crear una imgane personalizada con el contenedor
Reto 2
Crear un contenedor nuevo con la imagen personalizada de docker
Este contenedor tendra un volumen con una ruta en el disco del anfitrión (Bind)
Reto 3
Crear un repositorio git en la carpeta del anfitrión y unirlo con un repositorio en Github
Reto 4
Crear un contenedor mysql.
Crear una base de datos, para almacenar Coches. Los campos seran id, marca, modelo, color, km y precio
añadir almenos 10 coches a modo de contenido de muestra.
Reto 5
Crear en el repositorio Local un programa en python que se conecte a la base de datos y obtenga los registros de la mase de datos. – El programa debe listar los datos de los coches guardados en la base de datos de forma estetica.
ID MARCA MODELO COLOR KM PRECIO ———————————————————————— 1 Toyota Corolla Blanco 20000 15000 2 Honda Civic Rojo 30000 17000 3 Ford Focus Azul 25000 16000
Reto 6
Almacenar los datos de conexion a la base de datos en un archivo JSON y que el programa Python los lea de dicho archivo. * crear un nuevo archivo para la modificación. * Realiza un commit en cada paso
crear el .gitignore para que no suba el archivo con los datos de conexión.
Reto 7
Formatear la tabla para que quede mas estetica con la libreria
Crear un conetenedor Mongo y conectarse desde la terminal y utilizando MongoDB Crea la una bd e inserta en una colecci’on coches con el criterio de de campos del reto anterior Crear un Script de Python para leer los datos de colecciones de MongoDB y los imprima en una tabla.
Reto 9
Subir una imagen personaliza de nuestro contenedor mongodb al hub de Docker. En el Linux Parrot montar un contenedor con la imagen subida al hub.
Practicar variables de entorno, puertos y reinicios
1) Estructura del proyecto
Crea una carpeta de práctica:
mkdir mysql-pma-compose
cd mysql-pma-compose
2) Crear el archivo docker-compose.yml
Crea el fichero:
# Define los servicios (contenedores) que vamos a ejecutar
services:
# ----- SERVICIO MYSQL -----
mysql:
image: mysql:8.0 # Imagen oficial que se descargará de Docker Hub
container_name: mysql1 # Nombre fijo del contenedor (opcional, pero útil)
restart: unless-stopped # Reinicia el contenedor automáticamente salvo que lo pares tú
# Variables de entorno que usa la imagen de MySQL en su primer arranque
environment:
MYSQL_ROOT_PASSWORD: "RootPass_123!" # Contraseña del usuario root
MYSQL_DATABASE: "academia" # Base de datos que se crea automáticamente
MYSQL_USER: "alumno" # Usuario adicional que se creará
MYSQL_PASSWORD: "AlumnoPass_123!" # Contraseña del usuario alumno
# Volúmenes → permiten persistencia (los datos sobreviven aunque borres el contenedor)
volumes:
- mysql_data:/var/lib/mysql # Guarda los datos reales de MySQL fuera del contenedor
# Conecta el contenedor a una red Docker interna
networks:
- red-bbdd
# ----- SERVICIO PHPMYADMIN -----
phpmyadmin:
image: phpmyadmin:latest # Imagen oficial de phpMyAdmin
container_name: pma1
restart: unless-stopped
# Indica que MySQL debe arrancar antes (solo orden, no espera a que esté listo)
depends_on:
- mysql
# Variables que indican a phpMyAdmin a qué servidor MySQL conectarse
environment:
PMA_HOST: "mysql" # Nombre del servicio MySQL dentro de la red Docker
PMA_PORT: 3306 # Puerto interno de MySQL
# Publica puertos → expone el servicio al exterior
ports:
- "8080:80" # Puerto HOST:PUERTO_CONTENEDOR → http://localhost:8080
# Conecta phpMyAdmin a la misma red que MySQL para que puedan verse
networks:
- red-bbdd
# ----- DEFINICIÓN DE VOLÚMENES -----
volumes:
mysql_data: # Volumen gestionado por Docker (no es carpeta local visible normalmente)
# ----- DEFINICIÓN DE REDES -----
networks:
red-bbdd: # Red interna donde los contenedores se comunican por nombre (DNS interno)
Qué está pasando aquí (muy importante)
services: dos contenedores, uno para MySQL y otro para phpMyAdmin.
volumes: mysql_data guarda la base de datos fuera del contenedor (persistencia).
networks: red privada para que phpmyadmin pueda acceder a mysql por nombre.
depends_on: arranca primero MySQL (ojo: no garantiza “ready”, solo orden de arranque).
USE academia;
CREATE TABLE prueba (
id INT PRIMARY KEY AUTO_INCREMENT,
texto VARCHAR(50)
);
INSERT INTO prueba (texto) VALUES ("hola compose");
SELECT * FROM prueba;
Opción B: desde terminal (dentro del contenedor)
docker compose exec mysql mysql -u root -p
Comandos útiles para alumnos
docker compose ps
docker compose logs -f
docker compose exec mysql bash
docker compose exec phpmyadmin bash
docker compose down
docker compose down -v
En esta práctica vas a desplegar una pequeña infraestructura de servicios utilizando Docker y Docker Compose.
El objetivo no es únicamente “levantar contenedores”, sino comprender cómo se organizan los servicios, cómo se comunican entre ellos, cómo se almacenan los datos, cómo se exponen puertos al exterior y cómo se puede documentar y justificar una instalación técnica.
Durante la práctica se trabajará con servicios similares a los vistos en clase:
Servidor web HTTP con Apache.
PHP para ejecutar código dinámico.
MySQL como base de datos relacional.
phpMyAdmin como herramienta de administración.
MongoDB como base de datos NoSQL.
Mongo Express como herramienta de administración.
Redes Docker.
Volúmenes persistentes.
Variables de entorno.
Logs y comprobaciones.
Copias de seguridad básicas.
Documentación técnica.
2. Objetivos de aprendizaje
Al finalizar la práctica, el alumno deberá ser capaz de:
Explicar qué es Docker y para qué se utiliza.
Diferenciar una imagen de un contenedor.
Crear y ejecutar contenedores mediante Docker Compose.
Configurar servicios conectados entre sí.
Usar volúmenes para conservar datos.
Usar redes Docker para aislar servicios.
Configurar variables de entorno.
Desplegar una aplicación PHP conectada a MySQL.
Desplegar y consultar una base de datos MongoDB.
Comprobar el estado de los servicios mediante comandos.
Interpretar errores básicos mediante logs.
Documentar una instalación técnica de forma clara.
Defender oralmente el trabajo realizado.
3. Resultado final esperado
Al terminar la práctica deberás tener funcionando una infraestructura compuesta por varios contenedores:
Servicio
Tecnología
Puerto externo sugerido
Función
Web PHP
Apache + PHP
8080
Servidor web principal
MySQL
MySQL
3306 o solo interno
Base de datos relacional
phpMyAdmin
phpMyAdmin
8081
Administración de MySQL
MongoDB
MongoDB
27017 o solo interno
Base de datos NoSQL
Mongo Express
Mongo Express
8082
Administración de MongoDB
La aplicación PHP deberá mostrar una página web con información del alumno, conexión a MySQL y, opcionalmente, conexión a MongoDB.
4. Normas de entrega
El alumno deberá entregar:
Carpeta completa del proyecto.
Archivo docker-compose.yml.
Archivo .env.
Código fuente de la aplicación PHP.
Capturas de pantalla.
Documento de memoria en PDF.
Comandos utilizados.
Respuestas a las preguntas de reflexión.
Evidencias de funcionamiento.
Breve vídeo opcional de demostración.
5. Estructura recomendada del proyecto
Crea una carpeta llamada:
practica-docker-servicios-nombre-apellido
Dentro de ella deberás crear una estructura similar a esta:
¿Qué diferencia hay entre el puerto de la izquierda y el de la derecha en esta línea?
- "8080:80"
¿Para qué sirve volumes?
¿Qué pasaría con los datos de MySQL si no usásemos un volumen?
¿Qué hace depends_on?
¿Qué limitación tiene depends_on?
¿Para qué sirve definir una red propia llamada red_asir?
¿Por qué el servicio web puede conectarse a MySQL usando el nombre mysql?
10. Fase 5 — Script inicial de MySQL
Dentro de la carpeta mysql, crea el archivo init.sql.
Ejemplo:
CREATE TABLE IF NOT EXISTS alumnos ( id INT AUTO_INCREMENT PRIMARY KEY, nombre VARCHAR(100) NOT NULL, apellido VARCHAR(100) NOT NULL, curso VARCHAR(100) NOT NULL, fecha_registro TIMESTAMP DEFAULT CURRENT_TIMESTAMP );
¿Qué diferencia hay entre exportar e importar una base de datos?
¿Qué riesgos existen al restaurar una copia sobre una base de datos que ya contiene información?
¿Qué medidas tomarías antes de restaurar una copia en producción?
22. Fase 17 — Comprobación de red entre contenedores
Entra en el contenedor web:
docker exec -it asir_web_php bash
Instala herramientas de red si fuera necesario:
apt update apt install -y iputils-ping
Prueba conectividad:
ping mysql ping mongodb
Sal del contenedor:
exit
Preguntas de reflexión
¿Por qué podemos hacer ping mysql y no necesitamos conocer la IP del contenedor?
¿Qué papel hace el DNS interno de Docker?
¿Cambiaría la IP del contenedor si lo eliminamos y lo volvemos a crear?
¿Por qué es mejor usar nombres de servicio que direcciones IP?
23. Fase 18 — Seguridad básica
Analiza la configuración actual.
Responde:
¿Qué puertos están expuestos al equipo anfitrión?
¿Qué servicios son accesibles desde el navegador?
¿Tiene sentido exponer MySQL directamente al exterior?
¿Tiene sentido exponer MongoDB directamente al exterior?
¿Qué contraseñas son débiles?
¿Qué cambiarías si esto fuese un servidor real?
¿Qué riesgos tiene usar root para administrar la base de datos?
¿Qué riesgos tiene dejar herramientas como phpMyAdmin o Mongo Express accesibles públicamente?
Mejora obligatoria
Modifica el docker-compose.yml para que MySQL y MongoDB no publiquen puertos hacia el exterior.
Es decir, evita configuraciones como:
ports: - "3306:3306"
o:
ports: - "27017:27017"
Los servicios internos deben comunicarse por la red Docker, no necesariamente por puertos públicos.
Pregunta de reflexión
Si MySQL no tiene puerto publicado, ¿por qué phpMyAdmin puede seguir conectando con él?
24. Fase 19 — Personalización del proyecto
El alumno deberá personalizar la práctica.
Como mínimo deberá:
Cambiar el nombre de los contenedores.
Cambiar el nombre de la base de datos.
Cambiar usuario y contraseña.
Personalizar la página principal.
Insertar datos propios.
Añadir una nueva tabla en MySQL.
Añadir una nueva colección en MongoDB.
Documentar los cambios realizados.
Nueva tabla obligatoria
Crea una tabla llamada servicios.
Ejemplo:
CREATE TABLE IF NOT EXISTS servicios ( id INT AUTO_INCREMENT PRIMARY KEY, nombre VARCHAR(100) NOT NULL, imagen VARCHAR(100) NOT NULL, puerto VARCHAR(20), descripcion TEXT );
Inserta al menos cinco servicios:
Apache/PHP.
MySQL.
phpMyAdmin.
MongoDB.
Mongo Express.
Preguntas de reflexión
¿Qué campos has elegido para la tabla servicios?
¿Por qué has elegido esos campos?
¿Qué relación existe entre esta tabla y la infraestructura desplegada?
¿Cómo podrías mostrar esta tabla desde PHP?
25. Fase 20 — Ampliación opcional
Para subir nota, puedes realizar una o varias de estas mejoras.
Opción A — Añadir Nginx como proxy inverso
Añade un contenedor Nginx que actúe como punto de entrada.
Debe permitir acceder a la aplicación PHP desde otro puerto o ruta.
Opción B — Añadir Adminer
Añade Adminer como alternativa a phpMyAdmin.
Opción C — Añadir Redis
Añade Redis como servicio adicional y explica para qué se utiliza.
Objetivo: • Dejar Clawdbot instalado y funcional en Ubuntu. • Elegir entre dos modos de operación: 1) IA externa mediante API. 2) IA local mediante Ollama (ya presente en el sistema).
Nivel de privilegio necesario: usuario normal con terminal y sudo.
ACTUALIZAR EL SISTEMA
Primera regla de supervivencia Linux: actualizar repos.
Abre terminal y ejecuta:
sudo apt update && sudo apt upgrade -y
Esto asegura que tu zoológico de paquetes no tenga criaturas desactualizadas.
2. INSTALAR NODE.JS 22 CON NVM
Aquí usamos NVM (Node Version Manager), porque permite instalar versiones específicas sin contaminar el sistema.
Cierra terminal y ábrela de nuevo (o source ~/.bashrc si quieres ahorrar clicks mentales).
Instala Node.js 22:
nvm install 22
nvm use 22
Comprueba versión:
node -v
Si ves v22.x.x, perfecto.
3. INSTALAR CLAWDBOT EN UBUNTU
Clawdbot ofrece dos caminos: script o npm. Ambos llevan al mismo sitio.
Opción A — Instalar con script oficial:
curl -fsSL https://clawd.bot/install.sh | bash
Opción B — Instalar vía npm:
npm install -g clawdbot@latest
Verificar que existe:
clawdbot --version
Si devuelve una versión, el bot ya está en casa.
4. CONFIGURAR CLAWDBOT (ONBOARD)
El programa tiene un asistente interactivo para dejarlo listo.
Lánzalo:
clawdbot onboard --install-daemon
Durante este paso te preguntará por:
• Método de IA • Tokens o claves (si usas proveedores externos) • Integración con mensajería (opcional) • Arranque como daemon (servicio en segundo plano)
Aquí se bifurcan nuestros caminos.
5. ESCENARIO A: USANDO IA EXTERNA
En este modo Clawdbot actuaría como un cerebro sin neuronas propias, pidiendo a proveedores externos que piensen por él.
Requisitos previos:
• Haber generado tokens API en servicios como OpenAI, Anthropic, etc. • Tener anotada la clave (no la pierdas, equivale a la llave del laboratorio).
Durante el onboard, escoge:
→ “Proveedor externo” → Introduce el endpoint si lo pide → Introduce tu token API
Ejemplo típico con OpenAI (pseudointerfaz del asistente):
Select AI Provider:
1 - OpenAI
2 - Anthropic
3 - Others
Choice: 1
Enter API key: sk-********************************
(Ve al final del documento para ver el proceso paso a paso)
Una vez completado, Clawdbot usará internet para obtener las respuestas.
Prueba de funcionamiento:
clawdbot start
Si has integrado Telegram/Discord/CLI, deberías ver respuestas.
6. ESCENARIO B: USANDO OLLAMA LOCAL
En este modo Clawdbot usa el cerebro que ya existe en tu máquina, sin enviar nada fuera. Captura la idea de “computación autónoma”. Muy útil en ciberseguridad o en entornos sin internet.
Requisitos previos:
• Ollama ya instalado y funcionando. • Un modelo instalado (ej: llama3). • Servicio de Ollama escuchando en http://localhost:11434.
No explicamos cómo instalar Ollama porque ya está presente — solo necesitamos conectarlo.
Durante el onboard, selecciona:
→ “Ollama (local)”
El asistente preguntará por:
• URL del servidor (usar http://localhost:11434) • Nombre del modelo (ej: llama3, mistral, etc.)
Ejemplo textual:
Select AI Provider:
1 - OpenAI
2 - Anthropic
3 - Ollama (local)
Choice: 3
Enter Ollama Endpoint [http://localhost:11434]:
→ (dejar en blanco para usar el valor por defecto)
Enter Model Name: llama3
Tras eso, Clawdbot sabrá pedirle respuestas al servicio local de Ollama.
Prueba de funcionamiento:
clawdbot start
Si todo está en orden, al enviar una pregunta Clawdbot se la envía a Ollama y devuelve el resultado.
7. COMPROBACIONES ÚTILES
Ver si Clawdbot está funcionando como daemon:
systemctl --user status clawdbot
Ver logs para diagnosticar:
clawdbot logs
Ver si Ollama responde (solo en escenario B):
curl http://localhost:11434
Si responde JSON, Ollama está despierto.
8. USO COMPLEMENTARIO
Para integraciones con mensajería (Telegram, Discord, etc.) el asistente de onboard sirve de guía. Estas integraciones no influyen en si usas IA externa o IA local; son capas independientes del cerebro del bot.
INSTALACIÓN DE CLAWDBOT EN WINDOWS MEDIANTE WSL
Objetivo: • Iniciar un entorno Linux dentro de Windows • Instalar Node.js 22 • Instalar Clawdbot • Configurar IA externa u Ollama
HABILITAR WSL2
Abrir PowerShell como Administrador y ejecutar:
wsl --install
Esto habilita los componentes necesarios (Subsistema Linux + máquina virtual liviana). Después quizá te pida reiniciar.
Tras el reinicio, aparecerá Ubuntu en tu lista de aplicaciones o se te mostrará un prompt para configurar usuario y contraseña.
2. ACTUALIZAR UBUNTU
Abrir Ubuntu desde el menú de Windows y ejecutar:
sudo apt update && sudo apt upgrade -y
Esto pone al día los paquetes internos del nuevo Linux doméstico.
3. INSTALAR NVM + NODE.JS 22
NVM es el truco para tener la versión exacta de Node.js sin ensuciar el sistema.
Cerrar terminal y abrirla de nuevo (o source ~/.bashrc si tienes prisa).
Instalar Node.js 22:
nvm install 22
nvm use 22
Verificar con:
node -v
Si devuelve v22.x.x, vas bien.
4. INSTALAR CLAWDBOT
Aquí dos opciones, igual que en Linux nativo:
Opción A: Script oficial
curl -fsSL https://clawd.bot/install.sh | bash
Opción B: npm global
npm install -g clawdbot@latest
Verificar:
clawdbot --version
Si responde una versión, ya está dentro del laboratorio.
5. CONFIGURACIÓN INICIAL
Activar asistente interactivo:
clawdbot onboard --install-daemon
Este asistente pregunta por: • proveedor de IA • claves API para IA externa (si aplica) • integraciones con mensajería • arranque como daemon
(Ve al final del documento para ver el proceso paso a paso)
6. ESCENARIO A: USAR IA EXTERNA DESDE WSL
Este es el más sencillo. Sirve para OpenAI, Anthropic, etc.
Durante el onboard elegimos proveedor externo, metemos clave y listo. Después WSL puede salir a Internet sin problemas, así que Clawdbot obtiene las respuestas y las devuelve sin drama.
Prueba:
clawdbot start
7. ESCENARIO B: USAR OLLAMA DESDE WSL
Aquí hay un detalle curioso: Ollama debe correr en Windows nativo, no dentro de WSL, porque Ollama usa GPU y servicios del host. Actualmente Ollama no funciona bien dentro de WSL.
Por tanto, el flujo es:
Instalar Ollama en Windows
Lanzarlo (Windows abre un servicio en localhost:11434)
Desde WSL, Clawdbot le habla como si estuviera en la misma red
Comprobación desde WSL:
curl http://localhost:11434
Si devuelve JSON, la frontera entre Windows y Linux es porosa y amigable.
Durante el onboard, seleccionar: → “Ollama (local)” → Endpoint: http://localhost:11434 → Modelo: por ejemplo llama3
Después:
clawdbot start
Clawdbot enviará las preguntas desde WSL al servicio de Ollama en Windows, y te contestará sin salir jamás a la nube.
8. DIAGNÓSTICO Y LOGS
Estado del daemon:
systemctl --user status clawdbot
Logs:
clawdbot logs
9. NOTA
Usar WSL es cómodo para desarrollo o pruebas, pero no siempre ideal para producción: si cierras la terminal o el portátil duerme, los servicios mueren. Para sistemas siempre despiertos, vale más montar esto en una máquina Linux real, un NAS, o un pequeño Proxmox.
10. RESUMEN
Para que quede en un tiro limpio:
wsl --install
Abrir Ubuntu
sudo apt update && sudo apt upgrade -y
Instalar NVM + Node.js 22
Instalar Clawdbot
clawdbot onboard --install-daemon
Elegir IA externa o conectarlo a Ollama de Windows
Esto deja un entorno funcional donde Clawdbot vive en WSL y la IA puede vivir en la nube o en Windows según filosofía del usuario.
INSTALACIÓN DE CLAWDBOT EN macOS
Objetivo: • Instalar Clawdbot en macOS usando Terminal • Permitir funcionamiento con: (A) IA externa o (B) Ollama local previamente instalado
PREPARAR EL ENTORNO
Aunque no es estrictamente obligatorio, tener Homebrew facilita la vida. Homebrew es un gestor de paquetes que convierte el Mac en una especie de «Linux con diseño bonito».
Si ves v22.x.x, ya tienes el cerebro JavaScript funcional.
3. INSTALAR CLAWDBOT
Dos caminos disponibles:
Opción A — Script oficial:
curl -fsSL https://clawd.bot/install.sh | bash
Opción B — NPM global:
npm install -g clawdbot@latest
Verificar instalación:
clawdbot --version
Si devuelve una versión, Clawdbot ya vive en tu Mac.
4. CONFIGURACIÓN INICIAL
Iniciar asistente interactivo:
clawdbot onboard --install-daemon
Este asistente te pedirá tres tipos de decisiones:
Qué IA usar
Integraciones con mensajería (opcional)
Si deseas ejecutar como daemon (servicio)
(Ve al final del documento para ver el proceso paso a paso)
5. ESCENARIO A: IA EXTERNA EN macOS
Este modo envía las peticiones a un proveedor externo como OpenAI o Anthropic. Es útil si quieres modelos grandes sin instalarlos localmente.
Requisitos: token API del proveedor.
Durante onboarding, elegir:
AI Provider: OpenAI / Anthropic / Otros
Introducir tu clave API cuando te la pida.
Probar funcionamiento:
clawdbot start
Si has configurado una integración (Telegram, Discord, etc.) deberías recibir respuestas desde esas plataformas.
6. ESCENARIO B: OLLAMA EN macOS
Aquí no explicamos la instalación de Ollama porque ya está instalada según tu petición. Solo nos interesa cómo conectar.
Comprobación rápida de que Ollama está vivo:
curl http://localhost:11434
Si devuelve JSON, el servidor está en pie.
Durante el onboard, seleccionar:
AI Provider: Ollama (local)
Endpoint: http://localhost:11434
Model Name: llama3
Puedes usar cualquier modelo que tengas descargado (alto secreto: macOS tira especialmente bien con Mistral y Llama3 por tema de optimización ARM).
Probar Clawdbot:
clawdbot start
Cuando envíes mensajes verás que Clawdbot se convierte en una especie de diplomático entre tu terminal y el modelo local.
7. VERIFICACIÓN Y LOGS
Comprobar si corre como daemon (usuario):
launchctl list | grep clawdbot
Observar logs de Clawdbot:
clawdbot logs
Ver si Ollama responde (solo escenario B):
curl http://localhost:11434
8. NOTAS OPERATIVAS MAC
– macOS es actualmente uno de los mejores sistemas para IA local gracias al hardware ARM. – Clawdbot no requiere privilegios elevados para funcionar, solo permisos de usuario. – Si quieres integraciones persistentes (Telegram, Discord) conviene activar el modo daemon en el onboard.
9. RESUMEN
El procedimiento queda así:
Instalar Homebrew (opcional pero útil)
Instalar NVM
Instalar Node.js 22
Instalar Clawdbot
Ejecutar clawdbot onboard --install-daemon
Elegir IA externa u Ollama
Verificar con clawdbot start
Esta combinación te da un asistente local que piensa con modelos externos (si quieres potencia cloud) o con cerebros locales (si quieres privacidad y autonomía).
PROCESO DE INSTALACIÓN CLOAWBOT
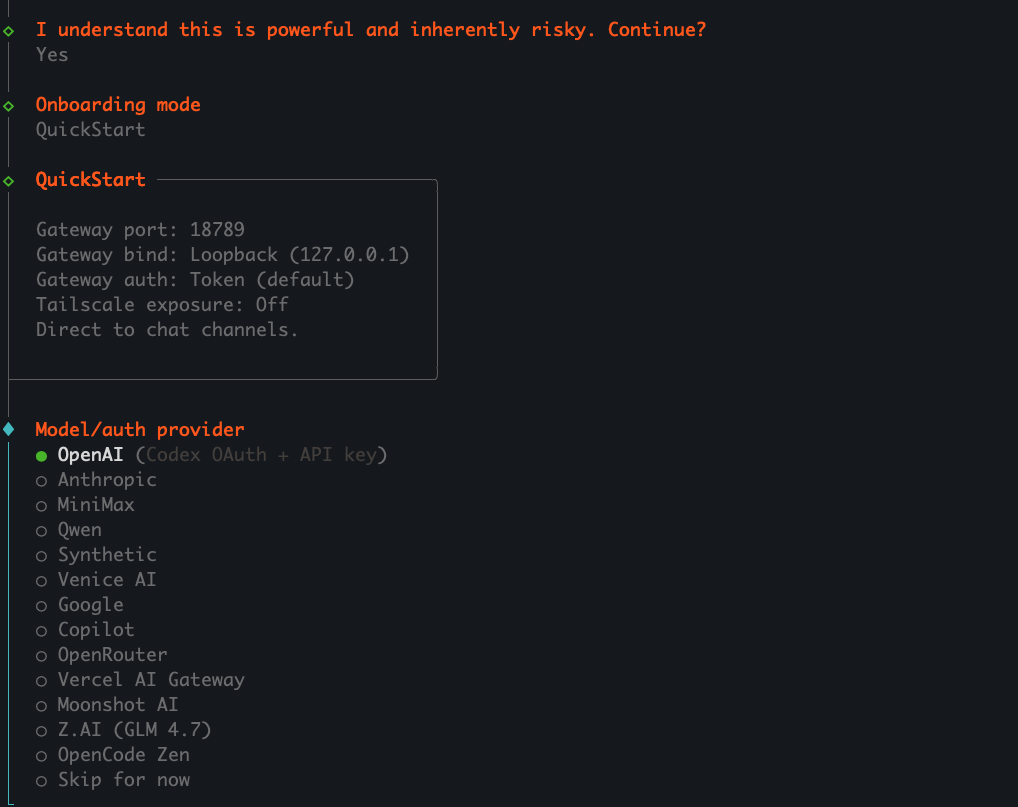
──────────────────────────────────────────── 📷 Imagen: Inicio del onboarding de Clawdbot (modo QuickStart) ────────────────────────────────────────────
Descripción: Se muestra el asistente de configuración inicial (onboard) en la terminal. La primera pregunta confirma que el usuario entiende la naturaleza del software (agente automatizado) y se le pide confirmar con Yes.
Elementos relevantes:
Onboarding mode: QuickStart
Configuración predeterminada del Gateway: Gateway port: 18789 Gateway bind: Loopback (127.0.0.1) Gateway auth: Token (default) Tailscale exposure: Off Direct to chat channels.
Significado operativo: En este modo, Clawdbot se ejecuta de forma local, no expone el servicio en la red, y autentica mediante token. Es ideal para principiantes o entornos personales.
Acciones recomendadas para el usuario:
Confirmar QuickStart en este punto si no requiere exposición de red.
Solo usuarios avanzados deben usar otros modos de gateway.
──────────────────────────────────────────── 📷 Imagen: Selección del proveedor de IA (Model/auth provider) ────────────────────────────────────────────
Descripción: Aquí el asistente solicita elegir qué proveedor dará servicio de inferencia al bot. Esta es la decisión clave entre IA externa (nube) o IA local.
Opciones visibles en la captura:
OpenAI
Anthropic
MiniMax
Qwen
Synthetic
Venice AI
Google
Copilot
OpenRouter
Vercel AI Gateway
Moonshot AI
Z.AI
OpenCode Zen
Skip for now
Significado operativo: Esto determina de dónde obtendrá Clawdbot sus respuestas. Si el usuario planea usar Ollama más adelante, puede elegir Skip for now y configurarlo posteriormente.
Acciones recomendadas para alumnos según escenario:
IA externa: seleccionar OpenAI o similar e introducir clave.
IA local con Ollama: seleccionar Skip for now y configurarlo después.
Entornos de prueba: también Skip for now si solo se quiere ver el panel.
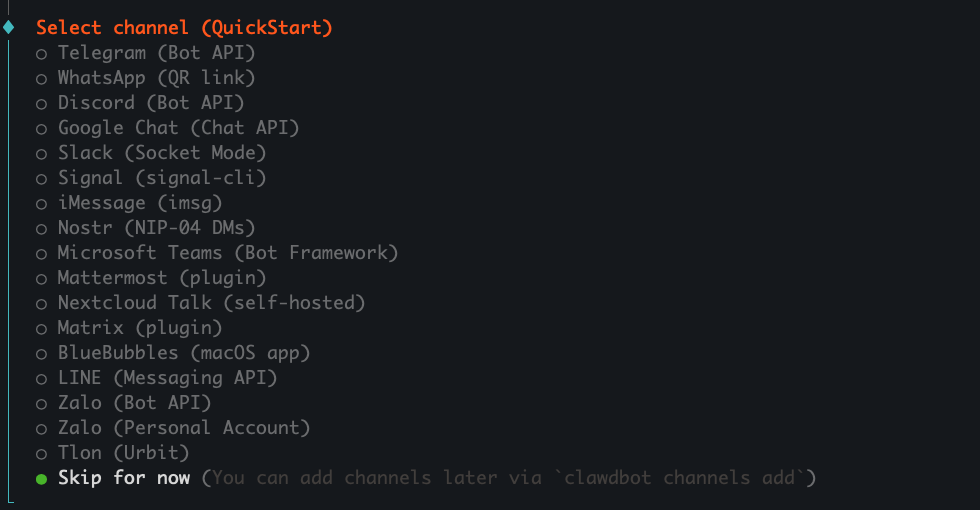
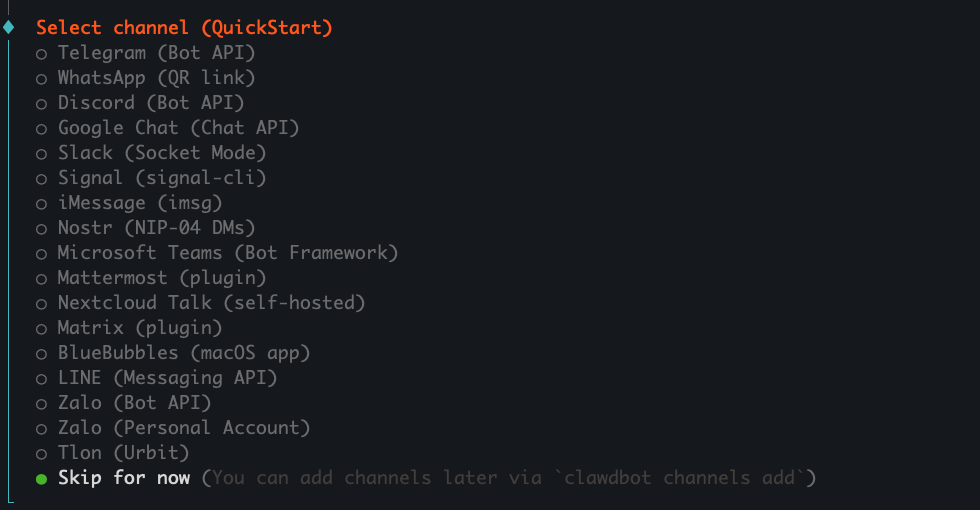
──────────────────────────────────────────── 📷 Imagen: Selección del canal de comunicación (QuickStart) ────────────────────────────────────────────
Descripción: El asistente ahora pide elegir a través de qué canal responderá el bot. Aparecen múltiples integraciones, algunas por API y otras por aplicaciones intermedias.
Opciones visibles en la captura:
Telegram
WhatsApp
Discord
Google Chat
Slack
Signal
iMessage
Microsoft Teams
Nextcloud Talk
Matrix
BlueBubbles
LINE
Zalo
TLon (Urbit)
Skip for now
Significado operativo: Cada integración requiere pasos adicionales (tokens, claves, o conectores). Para configurar primero el backend del bot, se puede usar Skip for now.
Acción recomendada para alumnos en laboratorio:
Seleccionar Skip for now la primera vez.
Más adelante añadir canales con: clawdbot channels add
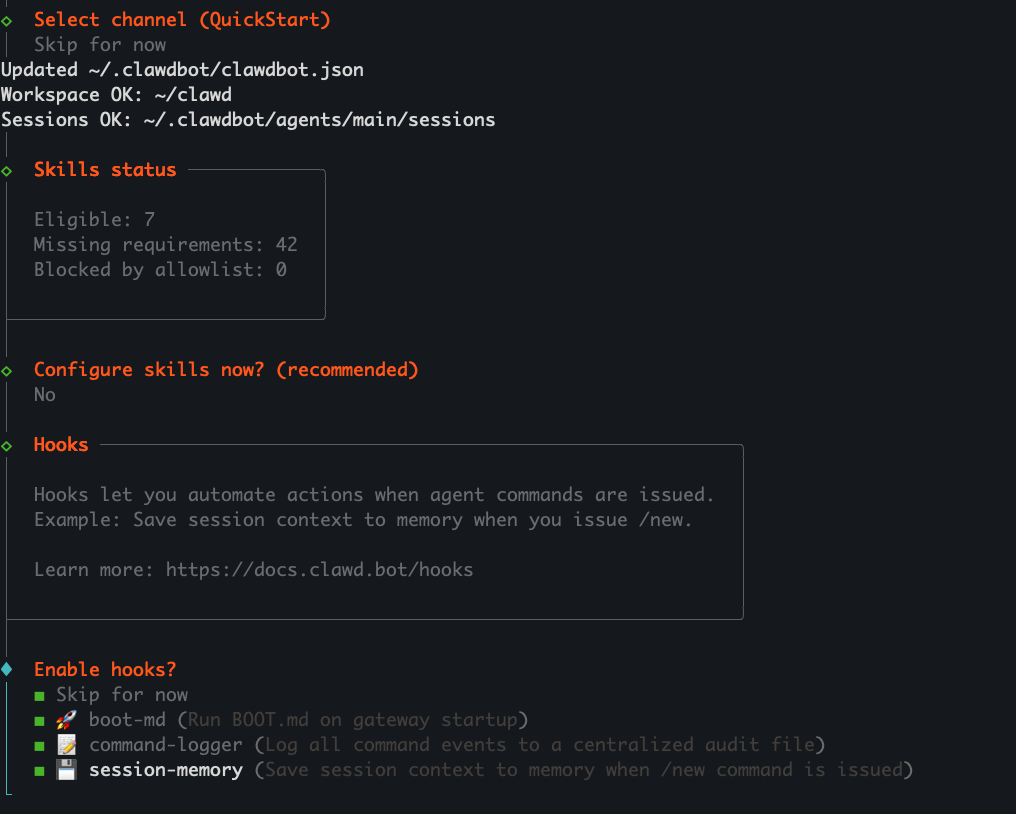
──────────────────────────────────────────── 📷 Imagen: Estado de habilidades (Skills Status) + Hooks ────────────────────────────────────────────
Descripción: Aquí se muestra la comprobación de habilidades del agente y la posibilidad de configurar Hooks.
Contenido clave:
Skills status:
Eligible: 7
Missing requirements: 42
Blocked by allowlist: 0
Configure skills now? → No
Hooks explicados con descripción funcional.
Significado operativo: Las habilidades son módulos que permiten a Clawdbot ejecutar acciones: leer archivos, ejecutar comandos, manipular memoria del agente, etc. Los Hooks permiten automatizar acciones en eventos internos.
Acciones recomendadas:
Para instalaciones iniciales: Configure skills now? → No Enable hooks? → Skip for now
Para uso avanzado, activar por ejemplo:
boot-md para ejecutar comandos al iniciar
command-logger para auditoría
session-memory para retención de contexto
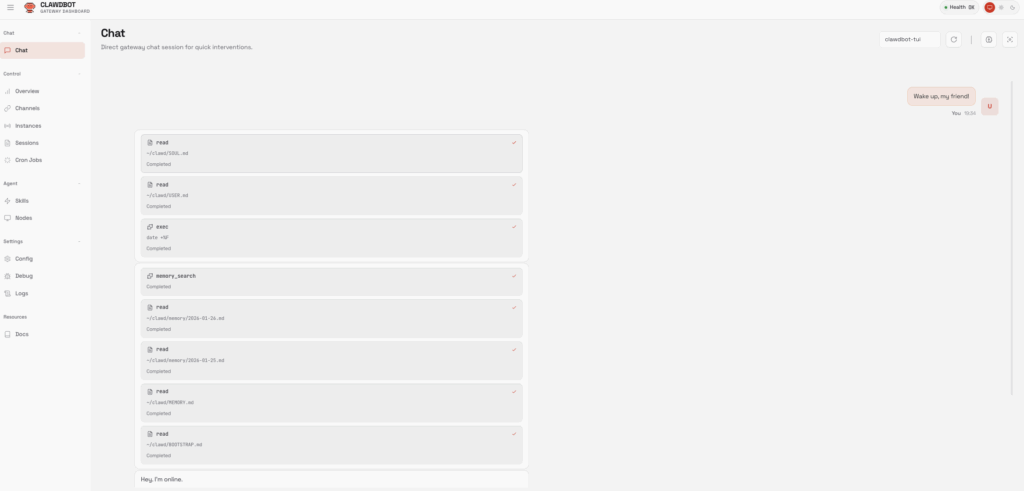
──────────────────────────────────────────── 📷 Imagen: Panel web de Clawdbot (Gateway Dashboard) ────────────────────────────────────────────
Descripción: Es la interfaz web del gateway de Clawdbot. Permite gestionar chat directo, sesiones, logs, habilidades, nodos y configuración del agente.
Elementos visibles en la captura:
Sección izquierda de navegación:
Chat
Overview
Channels
Sessions
Cron Jobs
Skills
Nodes
Config
Debug
Logs
Docs
Área principal mostrando ejecución de comandos:
read ~/clawd/SOUL.md
read ~/clawd/USER.md
exec date
memory_search
etc.
Significado operativo: El panel confirma que el gateway está funcional, el agente responde a comandos, y el estado del sistema es saludable (Health OK).
Acciones recomendadas:
Usar esta interfaz para verificar que el bot está funcionando.
Confirmar que la IA está generando respuestas en el panel (Hey, I'm online.).
Configurar canales o IA desde sección Config si se omitió al inicio.
La USS Horizon ha sido enviada a explorar un cúmulo estelar cercano a Andoria. La tripulación científica necesita un sistema de gestión para almacenar informes, muestras biológicas, registros de comunicaciones y perfiles de planetas. Como Oficial de Ingeniería Informática, tu misión es instalar un sistema MongoDB en el núcleo de datos del servidor de la nave, aprender a administrarlo por consola y cargar registros básicos.
FASE 1 — Instalación del Servidor MongoDB
Instalar MongoDB en el servidor Linux de la USS Horizon.
Procedimiento
Accede al servidor (terminal local o SSH).
Actualiza los paquetes del sistema:
sudo apt update && sudo apt upgrade -y
Añade la llave GPG del “repositorio de la Federación”:
Esto es excelente para enseñar que MongoDB es más “analítico” que un simple CRUD.
Índices
Compass → pestaña Indexes
Allí puedes:
Ver índices existentes
Crear uno nuevo desde GUI
Por ejemplo, crear índice en nombre:
Clic Create Index
Campo: nombre
Orden: Ascending
Crear
Esto deja caer la idea de rendimiento sin entrar en ingeniería pesada.
Estadísticas de colección
Compass tiene una pestaña Schema que permite:
Inferir estructura de documentos
Detectar tipos
Ver distribuciones
Ejemplo: podrían ver que clima es “Frío”, “Ártico”, etc. Visualmente ayuda a entender diversidad de documentos.
Práctica Guiada: “Exploración Visual de Datos con MongoDB Compass”
La USS Horizon ha completado su instalación del núcleo MongoDB en la sala de máquinas. Ahora la Sección de Ciencia quiere que los oficiales accedan a los registros desde una interfaz visual que permita agrupar, filtrar y entender datos sin necesidad de abrir un terminal. Te han asignado la operación.
FASE 1 — Preparar la Conexión desde Compass
Tu estación de trabajo local será el cliente de monitorización. Antes de iniciar la misión:
Asegúrate de que MongoDB está activo en el servidor de la nave:
sudo systemctl status mongod
Si estás en el mismo equipo donde instalaste MongoDB, podrás conectarte con localhost.
Si estás desde otro equipo del aula, necesitas la IP del servidor de la nave (por ejemplo 192.168.0.50).
Abre MongoDB Compass y en el campo de conexión escribe:
Para conexión local:
mongodb://localhost:27017
Para conexión remota en la red de aula:
mongodb://IP_DEL_SERVIDOR:27017
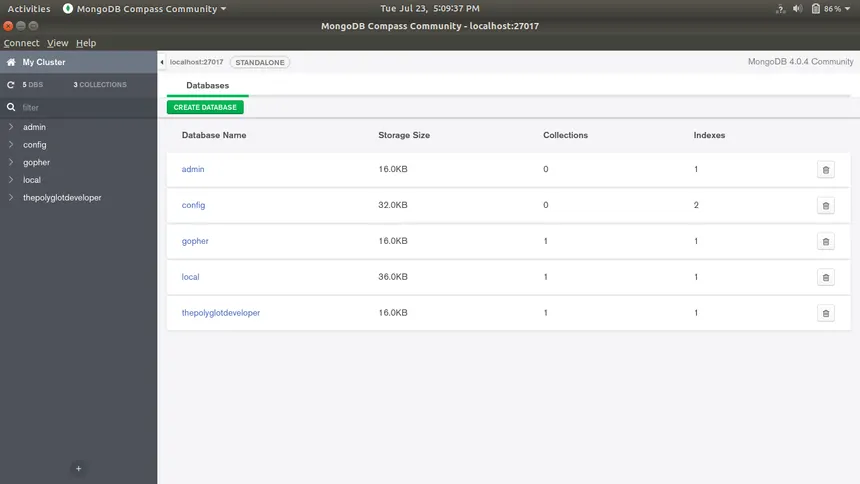
Pulsa Connect. Si todo va bien, deberías ver una lista de bases de datos en la barra lateral izquierda. Bienvenido al puente de mando.
FASE 2 — Exploración de la Biblioteca de Datos
Al conectarte, Compass mostrará un conjunto de bases predeterminadas del sistema.
Tu tarea inicial consiste en crear una estructura nueva que represente planetas registrados por la Federación.
Dirígete al botón de Create database
Nombre de la base de datos: fed_records
Nombre de la colección inicial: planets
Clic en Create
Acabas de crear un archivo científico dentro de la Biblioteca Estelar.
FASE 3 — Inserción de Datos Científicos
Ahora toca poblar la colección con datos reales que los sensores ya capturaron. Compass permite insertar datos con un editor visual.
Abre la colección planets y pulsa Insert Document.
Aparece un editor con un documento JSON. Rellénalo con:
Fíjate en un detalle interesante: no hay esquema rígido. MongoDB no te obliga a declarar columnas antes. Es como una biblioteca que acepta libros sin exigir número exacto de capítulos.
FASE 4 — Visualización y Edición de Documentos
Observa cómo Compass representa cada documento con su _id. Esa key es asignada automáticamente y sirve como identificador universal.
Ahora haz dos pruebas:
Edita un documento desde el icono Edit Document Cambia warp_capable de true a false en algún planeta no confirmado. Guarda y comprueba que Compass valida el JSON.
Elimina un planeta usando el botón Delete para simular que los registros debieron ser clasificadas tras un fallo diplomático.
Nadie en la Flota se escapa del poder del botón Delete.
FASE 5 — Consultas Visuales con Filtros
La Sección de Ciencia quiere consultar todos los planetas bajo Federation. Compass lo hace sin comandos: usa el buscador superior.
Pulsa el filtro visual y escribe:
{ "affiliation": "Federation" }
Pulsa Apply.
Si el universo está en orden, solo aparecerán planetas pertenecientes a la Federación.
FASE 6 — Agregaciones en la Sala de Análisis
Compass dispone de un módulo llamado Aggregations que permite crear pipelines de análisis (equivalente a map–reduce ligero).
Este tipo de vista enseña que MongoDB no solo guarda datos, también los procesa de forma analítica.
FASE 7 — Inferir Esquemas
Entra en la pestaña Schema dentro de la colección.
Compass examinará los documentos e inferirá:
Tipos de campos
Frecuencia de aparición
Valores más comunes
Esto simula cómo la Sección de Xenobiología analiza patrones entre especies sin necesidad de preguntar “¿cuál es la estructura del registro?”.
FASE 8 — Crear Índices
Ahora ve a la pestaña Indexes para crear un índice sobre el campo name.
Pulsa Create Index y configura:
Field: name
Sort: Ascending
Clic en Create.
MongoDB construirá el índice internamente. Tu planeta ahora se encuentra más rápido cuando alguien lo necesita. Rendimiento y diplomacia se dan la mano.
FASE 9 — Desconexión y Cierre de Misión
Cierra Compass. Detén el servicio MongoDB solo si el servidor necesita entrar en modo sigilo:
sudo systemctl stop mongod
La misión Compass se considera cumplida si has conseguido:
Con esto ya pueden hacer una pequeña “mini-API” o scripts de administración en PHP.
Uso de MongoDB desde Python
Instalar el driver de MongoDB para Python
Usaremos el driver oficial pymongo.
Pymongo vive fuera del zoológico de paquetes de Ubuntu, así que el mensaje de PEP 668 que viste antes aplica aquí. La forma elegante es montar un entorno virtual y meter ahí el driver.
Pasos rápidos:
Instala las herramientas para crear entornos:
sudo apt install python3-venv python3-full
Crea un entorno para tu proyecto Mongo:
python3 -m venv ~/.venvs/mongo
Actívalo:
source ~/.venvs/mongo/bin/activate
Ahora el pip dentro de ese entorno puede instalar lo que sea sin que Ubuntu proteste:
from pymongo import MongoClient
# 1. Crear cliente (conexión)
client = MongoClient("mongodb://localhost:27017")
# 2. Seleccionar base de datos y colección
db = client["fed_records"]
planets = db["planets"]
# 3. Insertar un documento
result = planets.insert_one({
"name": "Vulcan",
"species": "Vulcans",
"affiliation": "Federation",
"warp_capable": True
})
print("Insertado con ID:", result.inserted_id)
# 4. Obtener todos los documentos
print("\nLista de planetas:")
for planet in planets.find():
print(f"- {planet['name']} ({planet['affiliation']})")
# 5. Búsqueda filtrada
print("\nPlanetas de la Federación:")
for planet in planets.find({"affiliation": "Federation"}):
print(f"- {planet['name']}")
Ejemplo de pequeña “consulta analítica” (aggregations) en Python
Simulando algo tipo “cuántos planetas hay por alineación”:
pipeline = [
{"$group": {"_id": "$affiliation", "total": {"$sum": 1}}},
{"$sort": {"total": -1}}
]
print("\nResumen por alineación:")
for group in planets.aggregate(pipeline):
print(f"{group['_id']}: {group['total']}")
Este ejemplo encaja muy bien con lo que ya han visto en Compass (pestaña Aggregations).
Práctica Guiada:
“Un mismo universo de datos: PHP, Python y MongoDB Compass”
Antes de empezar, debe estar listo:
Servidor MongoDB instalado y funcionando en el servidor Linux: sudo systemctl status mongod
PHP instalado (por ejemplo PHP 8.x) y un servidor web (Apache) o PHP CLI.
Composer instalado: composer --version
Python 3 instalado: python3 --version
MongoDB Compass instalado en el equipo del alumno o en alguna máquina con entorno gráfico.
PARTE 1 – PHP + MongoDB
Fase 1.1 — Preparar el proyecto PHP
Crea una carpeta para el proyecto, por ejemplo: mkdir ~/mongo_php_lab cd ~/mongo_php_lab
Instala el driver oficial de MongoDB para PHP vía Composer: composer require mongodb/mongodb
Asegúrate de tener instalada y activada la extensión nativa de MongoDB en PHP:
Instalar extensión (si no está): sudo pecl install mongodb
Añadir en el php.ini correspondiente (CLI o Apache): extension=mongodb.so
Reiniciar Apache si usas servidor web: sudo systemctl restart apache2
Comprobar desde CLI: php -m | grep mongodb
Debe aparecer mongodb en la lista de módulos.
Fase 1.2 — Crear el script PHP
Crea el archivo mongo_php_lab.php dentro de ~/mongo_php_lab con este contenido:
<?php
require 'vendor/autoload.php';
use MongoDB\Client;
// 1. Conexión al servidor MongoDB
$client = new Client("mongodb://localhost:27017");
// 2. Selección de base de datos y colección
$database = $client->fed_records;
$collection = $database->planets;
echo "<h1>PHP + MongoDB: Laboratorio de planetas</h1>";
// 3. Insertar varios planetas (insertMany)
echo "<h2>1. Insertando planetas...</h2>";
$insertResult = $collection->insertMany([
[
'name' => 'Vulcan',
'species' => 'Vulcans',
'affiliation' => 'Federation',
'warp_capable' => true
],
[
'name' => "Qo'noS",
'species' => 'Klingons',
'affiliation' => 'Klingon Empire',
'warp_capable' => true
],
[
'name' => 'Ferenginar',
'species' => 'Ferengi',
'affiliation' => 'Ferengi Alliance',
'warp_capable' => true
]
]);
echo "Planetas insertados: " . $insertResult->getInsertedCount() . "<br>";
// 4. Listar todos los planetas
echo "<h2>2. Lista completa de planetas</h2>";
$cursor = $collection->find();
foreach ($cursor as $planet) {
echo "Nombre: " . $planet['name'] .
" | Especie: " . $planet['species'] .
" | Alineación: " . $planet['affiliation'] .
" | Warp: " . ($planet['warp_capable'] ? 'Sí' : 'No') .
"<br>";
}
// 5. Mostrar solo los de la Federación
echo "<h2>3. Planetas de la Federación</h2>";
$cursorFed = $collection->find(['affiliation' => 'Federation']);
foreach ($cursorFed as $planet) {
echo "Nombre: " . $planet['name'] . "<br>";
}
// 6. Cambiar un campo (warp_capable) para Vulcan
echo "<h2>4. Actualizando warp_capable de Vulcan a false</h2>";
$updateResult = $collection->updateOne(
['name' => 'Vulcan'],
['$set' => ['warp_capable' => false]]
);
echo "Documentos modificados: " . $updateResult->getModifiedCount() . "<br>";
// 7. Borrar un registro (Ferenginar)
echo "<h2>5. Borrando el planeta Ferenginar</h2>";
$deleteResult = $collection->deleteOne(['name' => 'Ferenginar']);
echo "Documentos eliminados: " . $deleteResult->getDeletedCount() . "<br>";
// 8. Lista final para comprobar cambios
echo "<h2>6. Lista final de planetas tras cambios</h2>";
$cursorFinal = $collection->find();
foreach ($cursorFinal as $planet) {
echo "Nombre: " . $planet['name'] .
" | Alineación: " . $planet['affiliation'] .
" | Warp: " . ($planet['warp_capable'] ? 'Sí' : 'No') .
"<br>";
}
Fase 1.3 — Ejecutar el script PHP
Opción A – Desde navegador (si usas Apache):
Copia el proyecto a la carpeta del servidor, por ejemplo: sudo cp -r ~/mongo_php_lab /var/www/html/
En el navegador, abre: http://IP_DEL_SERVIDOR/mongo_php_lab/mongo_php_lab.php
Opción B – Desde línea de comandos (CLI):
cd ~/mongo_php_lab
php mongo_php_lab.php
(La salida será texto plano, pero funcional para comprobar inserciones y cambios.)
Cuando termine esta parte, en la colección fed_records.planets deberían existir al menos:
Vulcan (warp_capable = false tras el update)
Qo'noS Y no debería estar Ferenginar (borrado).
PARTE 2 – Python + MongoDB
Ahora toca hacer lo mismo, pero desde Python, y además añadir una agregación por affiliation.
Fase 2.1 — Instalar pymongo
En el servidor o equipo donde ejecutes Python:
pip install pymongo
(si usas pip3, cámbialo por pip3)
Fase 2.2 — Crear el script Python
En tu home (o donde quieras), crea para el lab:
mkdir ~/mongo_python_lab
cd ~/mongo_python_lab
Crea el archivo mongo_python_lab.py con este contenido:
from pymongo import MongoClient
# 1. Conexión al servidor MongoDB
client = MongoClient("mongodb://localhost:27017")
# 2. Seleccionar base de datos y colección
db = client["fed_records"]
planets = db["planets"]
print("PYTHON + MongoDB: Laboratorio de planetas\n")
# 3. Insertar nuevos planetas
print("1) Insertando nuevos planetas...\n")
insert_result = planets.insert_many([
{
"name": "Andoria",
"species": "Andorians",
"affiliation": "Federation",
"warp_capable": True
},
{
"name": "Cardassia Prime",
"species": "Cardassians",
"affiliation": "Cardassian Union",
"warp_capable": True
}
])
print("IDs insertados:", insert_result.inserted_ids, "\n")
# 4. Listar todos los planetas
print("2) Lista completa de planetas:")
for planet in planets.find():
print(f"- {planet['name']} ({planet['affiliation']}) | Warp: {planet.get('warp_capable', 'N/A')}")
print()
# 5. Filtrar solo la Federación
print("3) Planetas de la Federación:")
for planet in planets.find({"affiliation": "Federation"}):
print(f"- {planet['name']}")
print()
# 6. Actualizar: poner warp_capable = True de nuevo en Vulcan (si existe)
print("4) Actualizando warp_capable de Vulcan a True...\n")
update_result = planets.update_one(
{"name": "Vulcan"},
{"$set": {"warp_capable": True}}
)
print("Documentos modificados:", update_result.modified_count, "\n")
# 7. Borrar un planeta concreto: Cardassia Prime
print("5) Borrando Cardassia Prime...\n")
delete_result = planets.delete_one({"name": "Cardassia Prime"})
print("Documentos eliminados:", delete_result.deleted_count, "\n")
# 8. Agregación por affiliation
print("6) Agregación: número de planetas por affiliation:\n")
pipeline = [
{"$group": {"_id": "$affiliation", "total": {"$sum": 1}}},
{"$sort": {"total": -1}}
]
for group in planets.aggregate(pipeline):
print(f"{group['_id']}: {group['total']} planetas")
Fase 2.3 — Ejecutar el script Python
Desde la carpeta del proyecto:
cd ~/mongo_python_lab
python3 mongo_python_lab.py
Observa:
Insertará Andoria y Cardassia Prime.
Luego listará todo lo que haya en fed_records.planets (incluyendo lo creado por PHP).
Volverá a poner Vulcan con warp_capable = True.
Borrará Cardassia Prime.
Mostrará la agregación por affiliation.
Con esto ya habrán hecho la misma lógica (y algo más) que en PHP, pero desde Python.
PARTE 3 – Verificación en MongoDB Compass
(La parte chula para cerrar el círculo)
Fase 3.1 — Conectarse con Compass
Abre MongoDB Compass.
En la pantalla inicial de conexión, usa:
Si Compass está en el mismo servidor que MongoDB:
mongodb://localhost:27017
Si Compass está en otro equipo de la red:
mongodb://IP_DEL_SERVIDOR:27017
Pulsa Connect.
Fase 3.2 — Explorar la base de datos fed_records
En la barra lateral izquierda, localiza la base de datos fed_records.
Entra en la colección planets.
Ahí deberías ver documentos provenientes de:
Las inserciones del script PHP.
Las inserciones del script Python.
Es decir, una mezcla de Vulcan, Qo’noS, Andoria, etc.
Fase 3.3 — Comprobar coherencia de los cambios
Verifica que:
Vulcan existe y tiene warp_capable = true (último cambio lo hizo Python).
Ferenginarno está (PHP lo borró).
Cardassia Primeno está (Python lo borró).
Modifica un documento desde Compass, por ejemplo:
Edita Qo'noS y cambia affiliation a "Klingon Empire (Updated)".
Guarda los cambios.
Vuelve a ejecutar el script Python: cd ~/mongo_python_lab python3 mongo_python_lab.py En la parte de “lista completa de planetas” verás la nueva affiliation de Qo'noS leída desde Python.
Si vuelves a ejecutar el script PHP, también verá la misma realidad.
Con esto se ve claramente que la fuente de verdad es MongoDB, y PHP / Python / Compass son solo distintas formas de mirar y manipular ese mismo universo de datos.
Un shell es un programa que permite al usuario comunicarse con el sistema operativo. Interpreta los comandos que escribimos y envía instrucciones al sistema para que las ejecute.
En sistemas GNU/Linux existen varios shells. Algunos de los más conocidos son:
Bash (Bourne Again SHell): el más utilizado en Linux, objetivo de este curso.
Zsh: muy usado en macOS y por usuarios que personalizan el terminal.
Fish: ofrece funcionalidades más modernas (autocompletado avanzado, etc.).
Dash: es un shell muy minimalista usado en muchos sistemas para scripts del sistema.
En nuestro caso trabajaremos con Bash porque es el estándar en Ubuntu y muy común en servidores Linux.
2. ¿Qué es Bash?
Bash es tanto un intérprete de comandos como un lenguaje de scripting. Esto significa que:
Podemos usarlo interactivamente, escribiendo comandos en la terminal.
Podemos guardar comandos en un archivo para ejecutarlos como un programa.
Gracias a esto, Bash es muy útil para:
Automatizar tareas repetitivas.
Administrar sistemas Linux.
Crear herramientas personalizadas.
Trabajar en entornos DevOps y ciberseguridad.
3. ¿Qué es un Script?
Un script es un archivo que contiene una secuencia de comandos. En lugar de escribirlos uno a uno en la terminal, los agrupamos para que se ejecuten automáticamente.
Un ejemplo básico de script sería:
echo "Hola, mundo!"
echo "Este es mi primer script."
Un script se ejecuta de principio a fin, permitiendo automatizar procesos como:
Copias de seguridad.
Instalación de software.
Monitorización del sistema.
Generación de informes.
Gestión de archivos.
4. ¿Por qué aprender Bash?
Dominar Bash abre la puerta a muchas áreas técnicas, como:
Después de entender qué es Bash y qué es un script, el siguiente paso es aprender a preparar correctamente el entorno de trabajo y ejecutar scripts de forma segura y ordenada.
1. Crear Scripts Correctamente
Un script no es más que un archivo de texto plano. Se puede crear con cualquier editor, desde los más simples hasta los más avanzados.
Editores recomendados:
nano (para trabajar en la terminal, muy sencillo)
vim (más avanzado, orientado a usuarios expertos)
Visual Studio Code (editor gráfico con sintaxis resaltada)
gedit o kate (editores gráficos simples)
Para crear un script:
nano mi_script.sh
Se recomienda usar la extensión .sh para identificar que es un script de shell, aunque no es obligatoria.
2. Añadir el Shebang
La primera línea del script debe indicar el intérprete que lo ejecutará. Esto se conoce como shebang.
Ejemplo:
#!/bin/bash
Esto garantiza que el script se ejecutará con Bash aunque el sistema use otro shell por defecto.
Otros ejemplos:
#!/bin/sh para un shell más compatible POSIX.
#!/usr/bin/env bash para localizar Bash dinámicamente en distintas máquinas.
3. Permisos de Ejecución
Un script recién creado no suele tener permisos de ejecución. Para poder ejecutarlo es necesario asignarlos.
Comando:
chmod +x mi_script.sh
Esto indica que el archivo puede ser ejecutado (x) por el usuario.
Para comprobar los permisos:
ls -l mi_script.sh
Ejemplo de salida:
-rwxr-xr-x 1 alumno alumno 57 ene 10 18:22 mi_script.sh
4. Ejecutar Scripts
Hay varias formas de ejecutar un script. Las más comunes son:
4.1. Ejecutarlo por ruta relativa
Si estamos en la misma carpeta del script:
./mi_script.sh
El ./ indica “ejecuta este archivo desde el directorio actual”.
4.2. Ejecutarlo por ruta absoluta
Ejemplo:
/home/alumno/scripts/mi_script.sh
Esto es útil en automatizaciones y servicios del sistema.
4.3. Ejecutarlo a través del intérprete
También podemos invocar directamente Bash:
bash mi_script.sh
Esto ignora permisos, pero exige que el script sea legible.
5. Organización del Entorno de Trabajo
Para no mezclar scripts con otros tipos de archivos, se recomienda crear una carpeta propia:
mkdir ~/scripts
cd ~/scripts
Aquí podemos almacenar scripts y añadir esta carpeta al PATH más adelante para ejecutarlos desde cualquier ubicación.
6. Variables de Entorno y el PATH
El PATH es una variable que indica dónde busca el sistema los programas ejecutables.
Para ver el PATH actual:
echo $PATH
Si añadimos nuestros scripts a una carpeta incluida en el PATH, podremos ejecutarlos sin escribir ./ ni rutas completas.
Más adelante veremos cómo añadir una ruta personalizada al PATH en el archivo .bashrc.
7. Comentarios y Documentación Interna
Es recomendable comentar el código para recordar qué hace cada parte. En Bash los comentarios se escriben con #.
Ejemplo:
#!/bin/bash
# Este script muestra un mensaje por pantalla
echo "Ejecutando mi script..."
Es buena práctica incluir una cabecera con información útil:
#!/bin/bash
# Nombre: backup_home.sh
# Autor: Nombre del alumno
# Descripción: Realiza una copia de seguridad del directorio /home
# Fecha: 10/01/2026
8. Problemas Comunes al Ejecutar Scripts
Durante este módulo suelen aparecer errores típicos:
bash: ./script.sh: Permission denied → Falta ejecutar chmod +x script.sh
command not found → El script no se encuentra o no es ejecutable
No such file or directory → Error en la ruta o en el nombre del archivo
bad interpreter: No such file or directory → El shebang apunta a una ruta incorrecta o se usa un archivo generado en Windows con saltos de línea incompatibles
Este último error aparece mucho cuando se editan scripts en Windows. Se resuelve con:
dos2unix script.sh
9. Ejemplo Completo de Script
Vamos a crear un script que pida un nombre y salude al usuario.
Crear el archivo:
nano saludo.sh
Contenido:
#!/bin/bash
echo "Introduce tu nombre:"
read nombre
echo "Hola $nombre, encantado de saludarte."
Dar permisos:
chmod +x saludo.sh
Ejecutarlo:
./saludo.sh
Ejercicios propuestos
Ejercicio 1: Crear un script llamado info.sh que muestre:
Ejercicio 2: Crear un script llamado crear_respaldo.sh que:
Cree una carpeta respaldo (si no existe)
Copie dentro todos los .txt del directorio actual
Ejercicio 3: Mover todos los scripts a ~/scripts/ y probar:
Ejecución con ./
Ejecución con ruta absoluta
Ejercicio 4 (opcional): Buscar qué es la variable PATH y para qué sirve.
Soluciones ejercicios
✅ Ejercicio 1
Enunciado: Crear un script llamado info.sh que muestre:
El usuario actual
El directorio donde se encuentra
La fecha actual
💡 Solución propuesta (info.sh)
#!/bin/bash
# Script: info.sh
# Muestra información básica del sistema y del usuario
echo "Usuario: $USER"
echo "Directorio actual: $(pwd)"
echo "Fecha actual: $(date +"%Y-%m-%d %H:%M:%S")"
Notas para clase:
$USER viene del entorno.
pwd muestra el directorio actual.
date formateado con +"%Y-%m-%d %H:%M:%S" muestra fecha y hora legibles.
✅ Ejercicio 2
Enunciado: Crear un script llamado crear_respaldo.sh que:
Cree una carpeta respaldo (si no existe)
Copie dentro todos los .txt del directorio actual
💡 Solución propuesta básica (crear_respaldo.sh)
#!/bin/bash
# Script: crear_respaldo.sh
# Crea una carpeta respaldo y copia todos los .txt dentro
# Crear carpeta si no existe
if [ ! -d "respaldo" ]; then
echo "Creando carpeta 'respaldo'..."
mkdir respaldo
else
echo "La carpeta 'respaldo' ya existe."
fi
# Copiar archivos .txt si existen
if ls *.txt >/dev/null 2>&1; then
echo "Copiando archivos .txt a 'respaldo'..."
cp *.txt respaldo/
echo "Copia completada."
else
echo "No se encontraron archivos .txt en el directorio actual."
fi
Ideas para comentar en clase:
[ ! -d "respaldo" ] → comprueba que NO exista el directorio.
ls *.txt >/dev/null 2>&1 → truco para comprobar si hay .txt sin mostrar errores.
cp *.txt respaldo/ → copia múltiple.
✅ Ejercicio 3
Enunciado: Mover todos los scripts a ~/scripts/ y probar:
Ejecución con ./
Ejecución con ruta absoluta
Aquí no hay “script solución”, sino comandos que los alumnos deben usar.
💡 Pasos y comandos
Crear la carpeta scripts en el home (si no existe):
mkdir -p ~/scripts
Mover los scripts (por ejemplo, info.sh y crear_respaldo.sh) desde el directorio actual:
mv info.sh crear_respaldo.sh ~/scripts/
Ir a la carpeta:
cd ~/scripts
Comprobar permisos (por si acaso):
chmod +x info.sh crear_respaldo.sh
Ejecutar con ruta relativa (estando dentro de ~/scripts):
./info.sh
./crear_respaldo.sh
Ejecutar con ruta absoluta (desde cualquier sitio):
/ home /usuario/scripts/info.sh
Sustituyendo usuario por el usuario real, por ejemplo:
/home/alumno/scripts/info.sh
✅ Ejercicio 4
Enunciado: Buscar qué es la variable PATH y para qué sirve.
Aquí puedes darles una explicación de solución tipo “teoría corregida”.
💡 Explicación-solución
La variable PATH:
Es una variable de entorno que contiene una lista de rutas separadas por :
Indica a la shell en qué directorios buscar ejecutables cuando escribimos un comando sin ruta.
Por ejemplo, si escribes:
ls
La shell busca un archivo ejecutable llamado ls en cada ruta del PATH, en orden.



![[Reto] – Despliegue de servicios con Docker y Docker Compose](https://laaventuradeaprender.com/wp-content/uploads/2026/06/b2427176-50e6-4af6-ada1-f4903698014f.png)