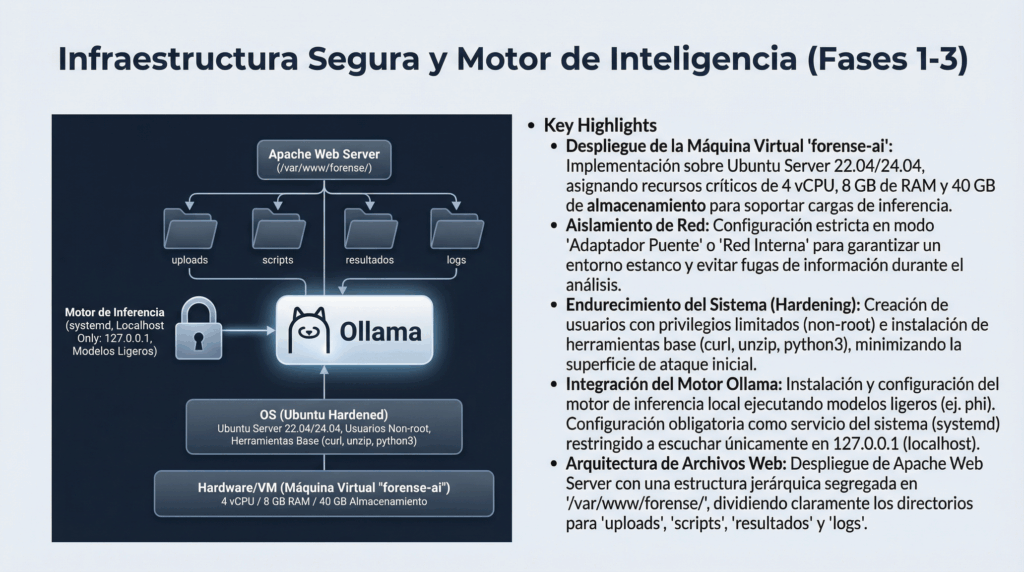
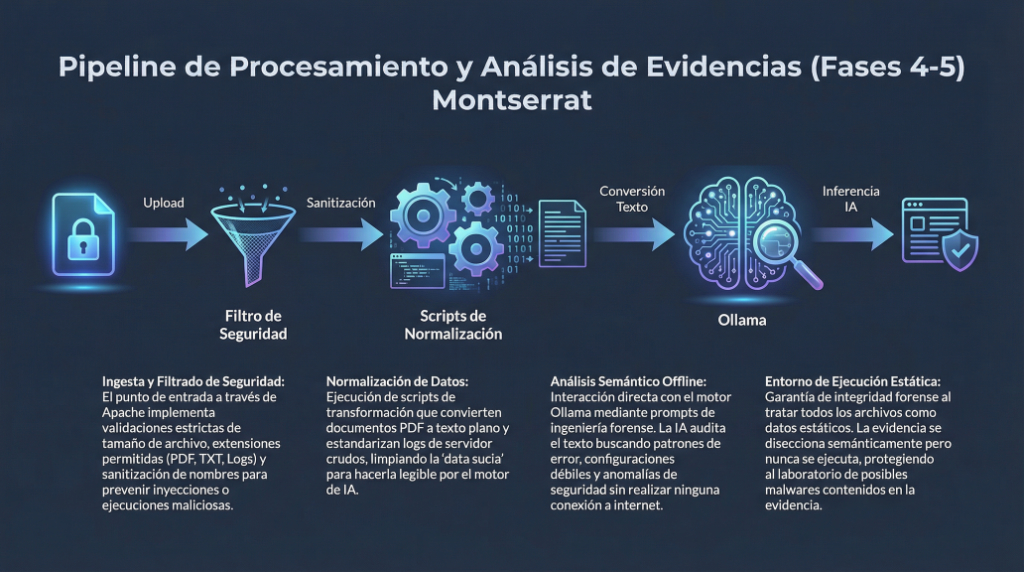
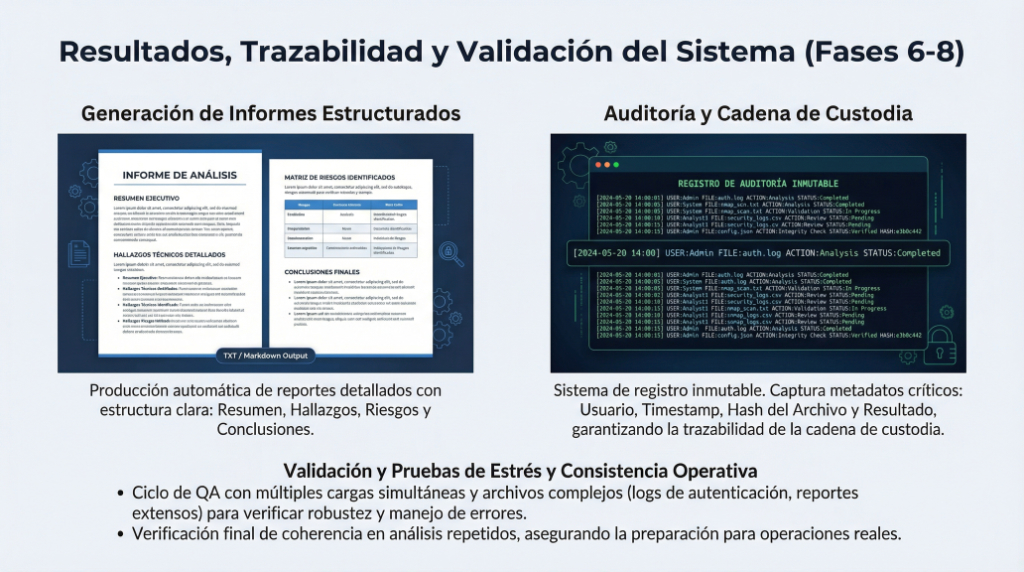
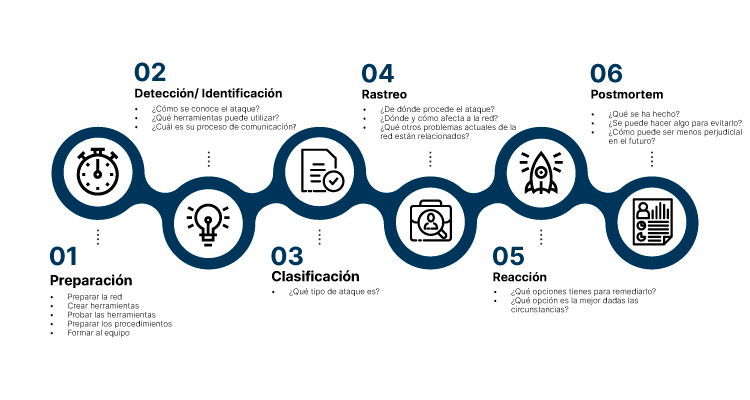
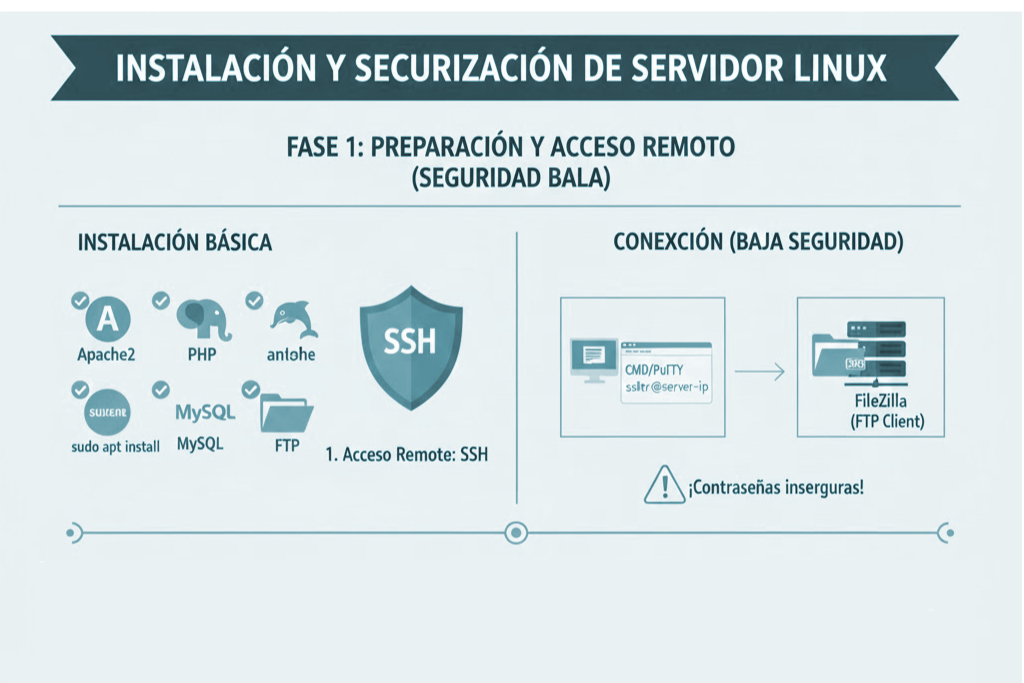
En entornos Linux de servidor, la configuración de red es un elemento crítico. Un error puede dejar el sistema incomunicado, inaccesible por SSH o fuera de la red. En Ubuntu Server moderno, la gestión de red se realiza mediante Netplan, que utiliza archivos YAML para definir cómo se configuran las interfaces.
En administraciones reales, cambiar entre IP dinámica (DHCP) y IP estática es una tarea habitual:
- Laboratorios → DHCP automático
- Servidores → IP fija y controlada
- Máquinas virtuales → cambios frecuentes
- Entornos de pruebas → configuraciones rápidas
Automatizar esta tarea reduce errores humanos y permite aplicar buenas prácticas de administración.
Se te pide desarrollar un script en Bash interactivo que permita:
- Cambiar una interfaz de red entre DHCP y IP estática
- Solicitar datos al usuario
- Validar entradas básicas
- Generar automáticamente el archivo de configuración Netplan
- Aplicar los cambios con
netplan apply - Crear copias de seguridad antes de modificar la configuración
- Ofrecer un menú interactivo
Requisitos técnicos
El script debe:
- Ejecutarse únicamente como root
- Verificar que existe el archivo de Netplan
- Permitir elegir entre:
- Configuración DHCP
- Configuración IP estática
- Salir
- En modo IP estática debe solicitar:
- Dirección IP
- Máscara en formato CIDR
- Gateway
- DNS
- Confirmar datos antes de aplicar cambios
- Crear copia de seguridad automática del archivo original
- Mostrar el archivo generado antes de aplicar
- Aplicar configuración con
netplan apply - Gestionar errores básicos
Restricciones
- El script debe estar escrito íntegramente en Bash
- No se permite editar Netplan manualmente fuera del script
- No se permite copiar directamente soluciones externas
- Debe funcionar en Ubuntu Server con Netplan
Análisis de solución
Una vez terminado tu script puedes comparalo con el ejemplo de solución.
Deberás:
- Comparar tu solución con la propuesta
- Detectar mejoras posibles
- Identificar:
- Validaciones adicionales
- Buenas prácticas usadas
- Manejo de errores
- Estructura del código
- Modularización en funciones
El objetivo no es solo que funcione… sino entender cómo se escribe un script robusto de administración real.
Ejemplo de solucion
1. Idea general del script
El script en Bash hará:
- Detectar qué archivo de Netplan estoy usando (normalmente algo como
/etc/netplan/00-installer-config.yaml). - Mostrar un menú en consola:
- Configurar IP estática
- Configurar IP dinámica (DHCP)
- Salir
- Según la opción:
- Pedirá los datos necesarios (IP, máscara, gateway, DNS) si es estática.
- Generará un archivo YAML de Netplan con esa configuración.
- Ejecutará
netplan applypara aplicar los cambios.
IMPORTANTE:
- Necesitaré ejecutarlo como
root(sudo ./script.sh), porque va a escribir en/etc/netplan/.- Debo saber el nombre de la interfaz (por ejemplo
enp0s3oens33). Lo puedo consultar medianteip aoifconfig
2. Ejemplo de archivo Netplan (referencia rápida)
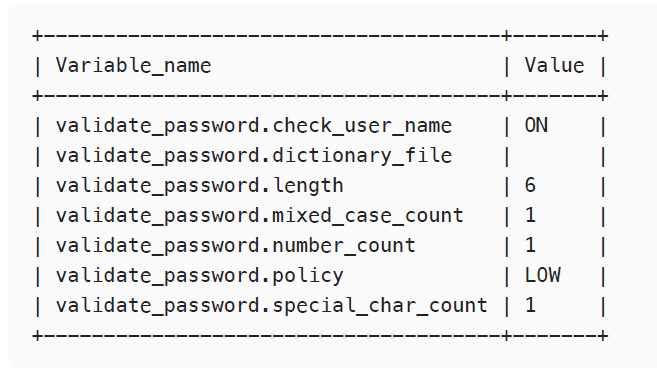
Consulto mi archivo actual de Netplan mediante ls /etc/netplan primero y sudo cat /etc/netplan/50-cloud-init.yaml obteniendo las siguientes:
DHCP (IP dinámica)
network:
version: 2
ethernets:
enp0s3:
dhcp4: true«
IP estática
network:
version: 2
renderer: networkd
ethernets:
enp0s3:
dhcp4: false
addresses:
- 192.168.1.50/24
gateway4: 192.168.1.1
nameservers:
addresses:
- 8.8.8.8
- 1.1.1.1
Nuestro script generará algo parecido según la opción que elijas.
3. Script completo en Bash
Mediante sudo nano script_cambiar_ip_netplan.sh,creo el script dentro de mi carpeta de scripts con ruta /home/mario/scripts. En su interior introduzco los siguientes parámetros de configuración:
#!/usr/bin/env bash
# ==========================================================
# Script para cambiar entre IP estática y dinámica (DHCP)
# en Ubuntu Server usando Netplan.
#
# Úsalo con:
# sudo ./cambiar_ip_netplan.sh
# ==========================================================
# ---------- CONFIGURACIÓN BÁSICA A EDITAR ----------
# Nombre de la interfaz de red (ajústalo a tu caso: enp0s3, ens33, etc.)
INTERFACE="enp0s3"
# Archivo de Netplan a usar
NETPLAN_FILE="/etc/netplan/50-cloud-init.yaml"
# Si tu sistema usa otro, cámbialo aquí, por ejemplo:
# NETPLAN_FILE="/etc/netplan/50-cloud-init.yaml"
# ---------------------------------------------------
# Comprueba que se ejecuta como root
if [[ "$EUID" -ne 0 ]]; then
echo "Este script debe ejecutarse como root. Usa: sudo $0"
exit 1
fi
# Comprueba que existe el archivo de Netplan
if [[ ! -f "$NETPLAN_FILE" ]]; then
echo "ERROR: No se encuentra el archivo de Netplan: $NETPLAN_FILE"
echo "Revísalo y edita el script para apuntar al archivo correcto."
exit 1
fi
# Función para pausar
pausa() {
echo
read -rp "Pulsa Enter para continuar..." _;
}
# Función para configurar DHCP
configurar_dhcp() {
echo "Configurando interfaz $INTERFACE con IP dinámica (DHCP)..."
# Hacemos copia de seguridad
cp "$NETPLAN_FILE" "${NETPLAN_FILE}.backup_$(date +%Y%m%d_%H%M%S)"
cat > "$NETPLAN_FILE" <<EOF
network:
version: 2
renderer: networkd
ethernets:
$INTERFACE:
dhcp4: true
EOF
echo "Archivo Netplan generado:"
echo "----------------------------------------"
cat "$NETPLAN_FILE"
echo "----------------------------------------"
echo "Aplicando cambios con netplan apply..."
netplan apply
if [[ $? -eq 0 ]]; then
echo "Configuración DHCP aplicada correctamente."
else
echo "Hubo un error al aplicar la configuración. Revisa el archivo YAML."
fi
pausa
}
# Función para configurar IP estática
configurar_estatica() {
echo "Configuración de IP estática para la interfaz: $INTERFACE"
echo
read -rp "Introduce la IP (ej: 192.168.1.50): " IP
read -rp "Introduce la máscara en CIDR (ej: 24 para 255.255.255.0): " CIDR
read -rp "Introduce la puerta de enlace (gateway) (ej: 192.168.1.1): " GATEWAY
read -rp "Introduce DNS (separados por espacio, ej: 8.8.8.8 1.1.1.1): " DNS_ENTRIES
# Validaciones básicas (muy simples)
if [[ -z "$IP" || -z "$CIDR" || -z "$GATEWAY" || -z "$DNS_ENTRIES" ]]; then
echo "Algún campo está vacío. Cancelando configuración."
pausa
return
fi
echo
echo "Resumen de la configuración estática:"
echo " IP: $IP/$CIDR"
echo " Gateway: $GATEWAY"
echo " DNS: $DNS_ENTRIES"
echo
read -rp "¿Es correcto? (s/n): " CONFIRM
if [[ "$CONFIRM" != "s" && "$CONFIRM" != "S" ]]; then
echo "Configuración cancelada."
pausa
return
fi
# Creamos una copia de seguridad del archivo actual
cp "$NETPLAN_FILE" "${NETPLAN_FILE}.backup_$(date +%Y%m%d_%H%M%S)"
# Generamos lista YAML de DNS
DNS_YAML=""
for dns in $DNS_ENTRIES; do
DNS_YAML+=" - $dns"$'\n'
done
# Escribimos nueva configuración en el archivo Netplan
cat > "$NETPLAN_FILE" <<EOF
network:
version: 2
renderer: networkd
ethernets:
$INTERFACE:
dhcp4: false
addresses:
- $IP/$CIDR
gateway4: $GATEWAY
nameservers:
addresses:
$(echo -n "$DNS_YAML")
EOF
echo "Archivo Netplan generado:"
echo "----------------------------------------"
cat "$NETPLAN_FILE"
echo "----------------------------------------"
echo "Aplicando cambios con netplan apply..."
netplan apply
if [[ $? -eq 0 ]]; then
echo "Configuración estática aplicada correctamente."
else
echo "Hubo un error al aplicar la configuración. Revisa el archivo YAML."
fi
pausa
}
# Menú principal
while true; do
clear
echo "=============================================="
echo " Cambiar configuración de red (Netplan)"
echo " Interfaz actual: $INTERFACE"
echo " Archivo Netplan: $NETPLAN_FILE"
echo "=============================================="
echo "1) Usar IP dinámica (DHCP)"
echo "2) Usar IP estática"
echo "3) Salir"
echo "----------------------------------------------"
read -rp "Elige una opción [1-3]: " OPCION
case "$OPCION" in
1)
configurar_dhcp
;;
2)
configurar_estatica
;;
3)
echo "Saliendo..."
exit 0
;;
*)
echo "Opción no válida."
pausa
;;
esac
done
4. Cómo usarlo paso a paso
- Crear el archivo del script:
sudo nano script_cambiar_ip_netplan.shPega el contenido anterior, guarda y cierra (Ctrl+O, Enter,Ctrl+X). - Dar permisos de ejecución:
sudo chmod +x script_cambiar_ip_netplan.sh - Editar variables según tu caso:
- Abre el script y cambia:
INTERFACE="enp0s3" NETPLAN_FILE="/etc/netplan/50-cloud-init.yaml"Pon el nombre de la interfaz que tengas y el archivo real de Netplan.
- Abre el script y cambia:
- Ejecutar el script como root:
sudo ./script_cambiar_ip_netplan.sh - Elegir opción del menú:
- Si eliges estática, introduce:
- IP (ej.
192.168.0.50) - CIDR (ej.
24) - Gateway (ej.
192.168.0.1) - DNS (ej.
8.8.8.8 1.1.1.1)
- IP (ej.
- Si eliges estática, introduce:
5. Recomendaciones para no quedarte “sin red”
- Haz pruebas estando en consola local (no por SSH), para que si te quedas sin red aún tengas acceso.
- El script crea copias de seguridad del YAML original con nombre tipo:
/etc/netplan/00-installer-config.yaml.backup_20251206_153055
- Si algo sale mal, puedes restaurar:
sudo cp /etc/netplan/00-installer-config.yaml.backup_YYYYMMDD_HHMMSS /etc/netplan/00-installer-config.yaml sudo netplan applyM
6. Evidencias de funcionamiento del Script en mi UbuntuServer.
- A continuación adjunto distintas capturas de pantallas de mi UbuntuServer en las que puedo seleccionar las distintas opciones (yo no asignaré IP fija en este momento, ya que quiero seguir trabajando con mi server mediante DHCP)
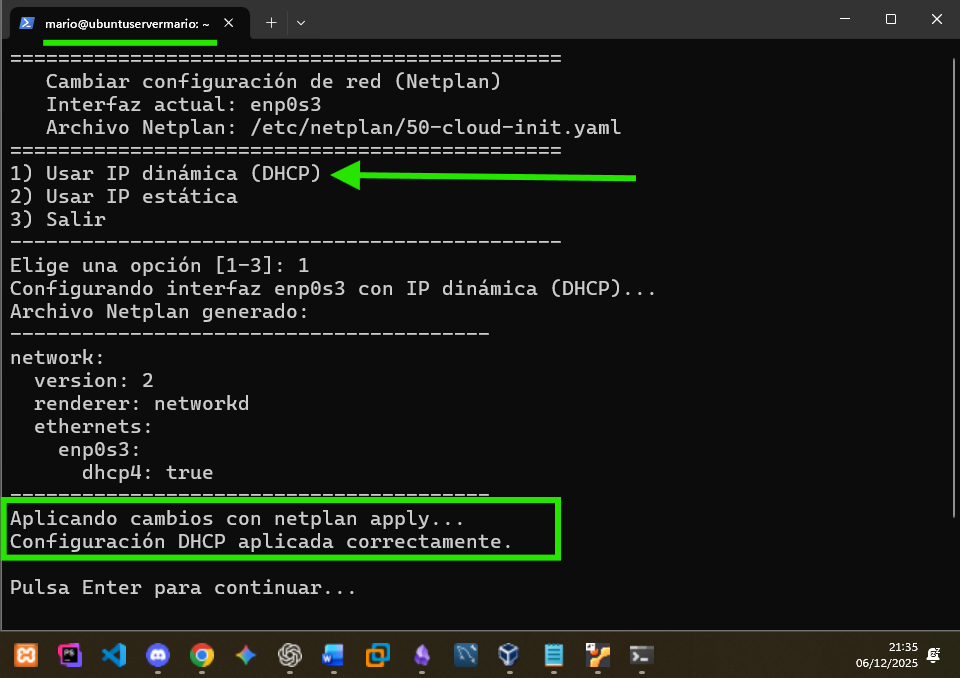
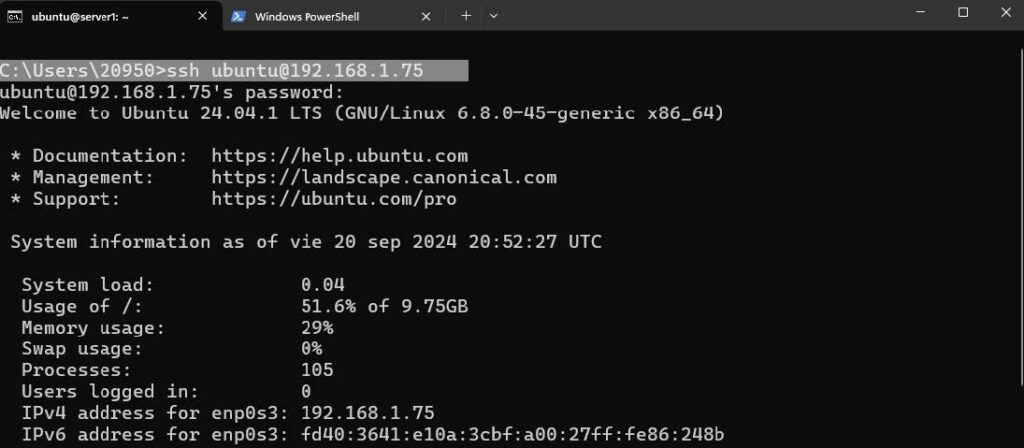
Arrancamos el script seleccionado la config por DHCP:
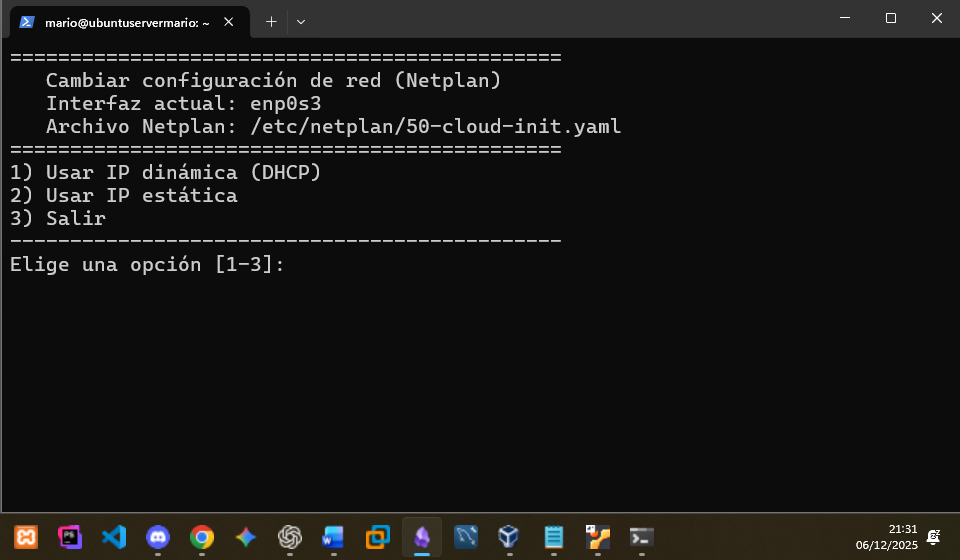
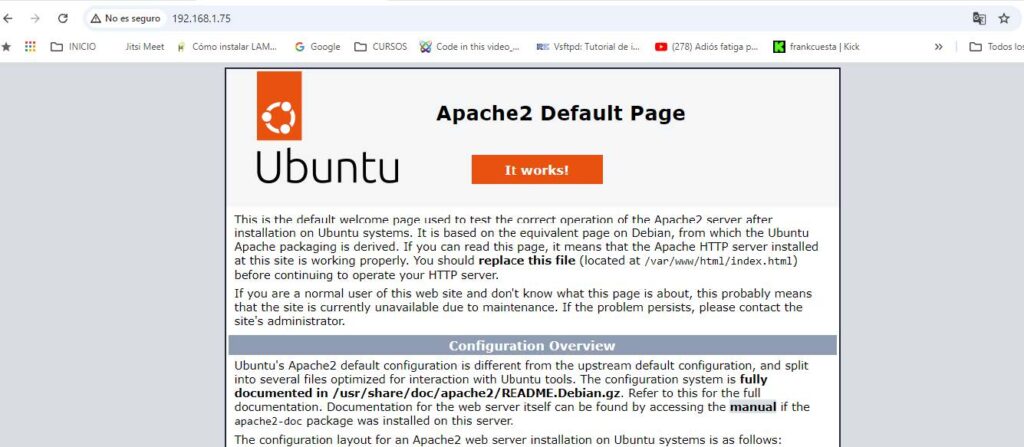
Aquí vemos las opciones que nos ofrece, sin seleccionar ninguna:
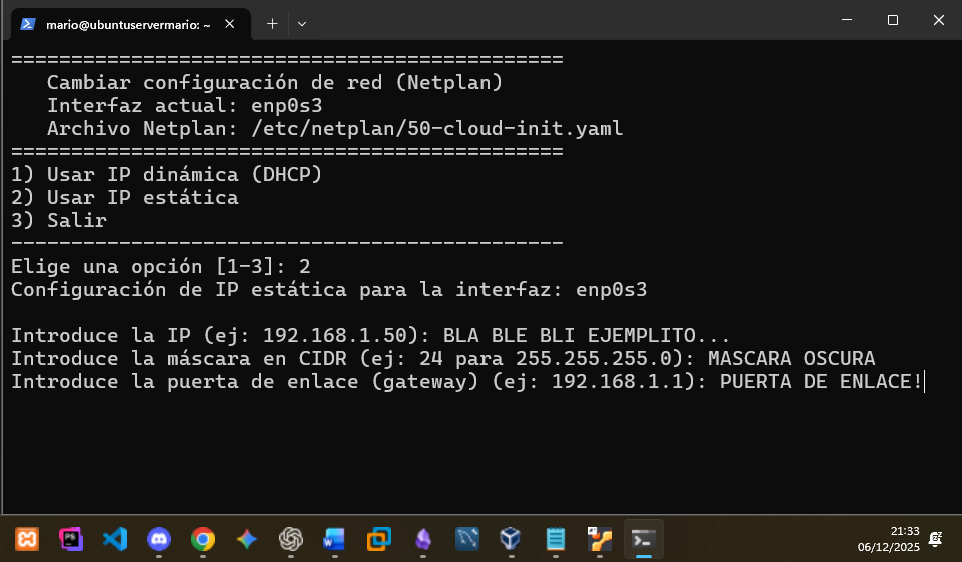
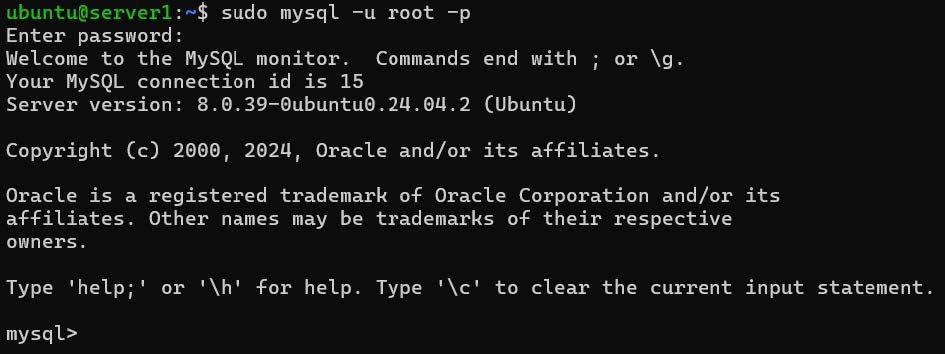
En esta simulamos introducir los parámetros para configurar IP estática:
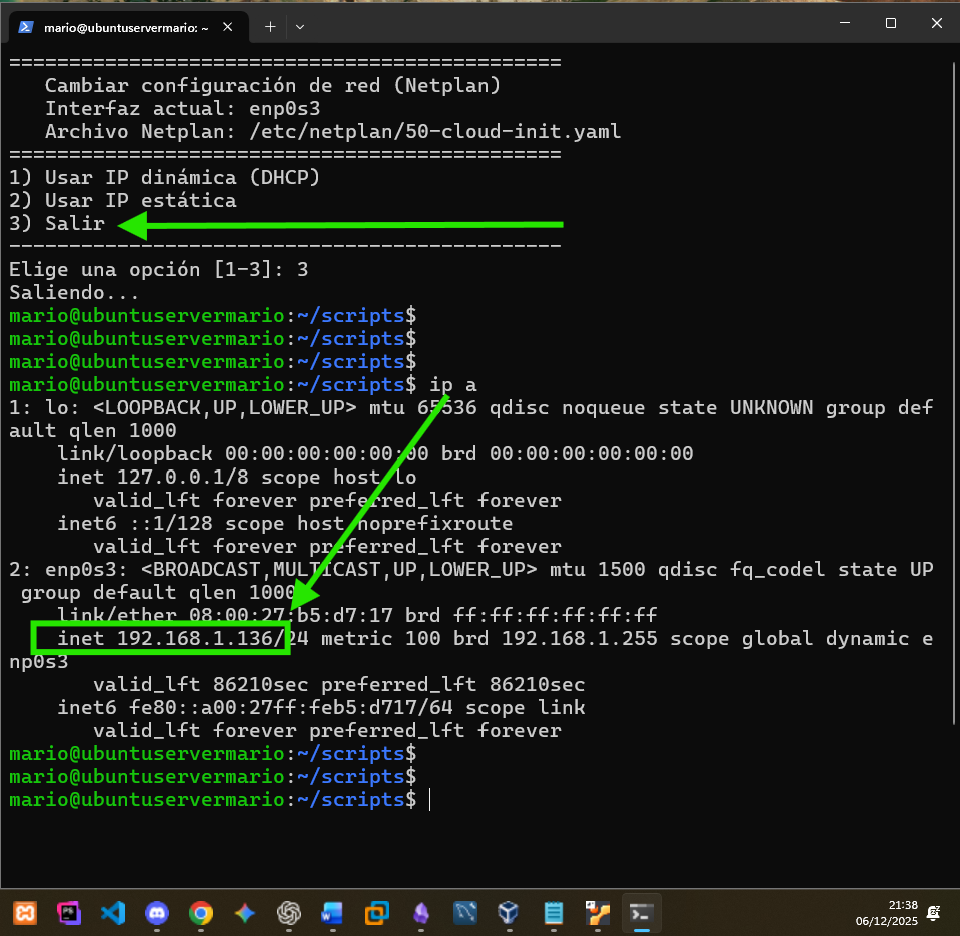
Y en esta última seleccionamos la opción de salir, y hacemos un ip a donde evidencia la asignación de IP por DHCP:
![[Reto] – Aletheia un Sistema de Auditoría y Análisis Forense Automatizado](https://laaventuradeaprender.com/wp-content/uploads/2026/01/da680bf6-26c1-4785-88c6-6cf35b86bcca.png)