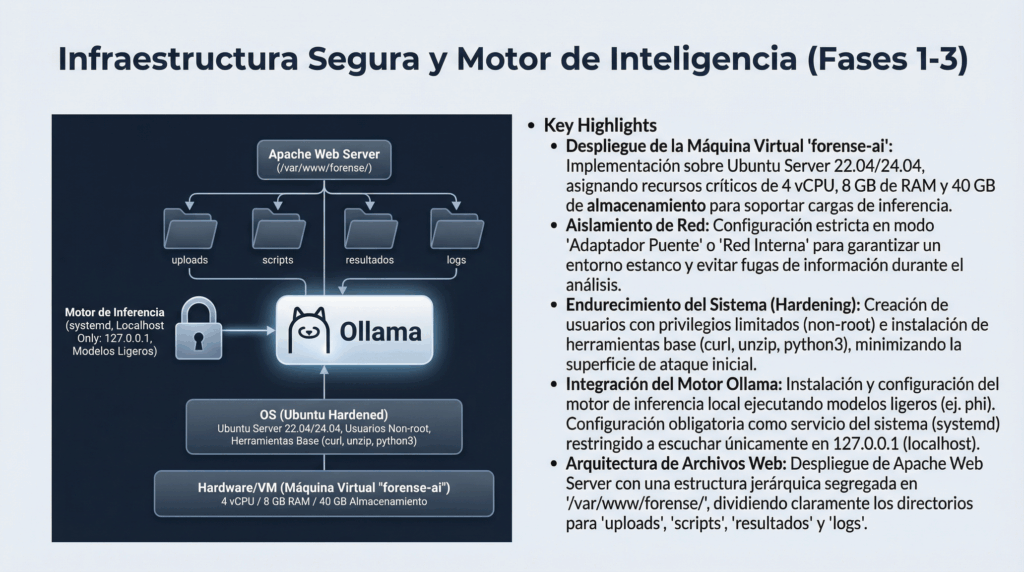
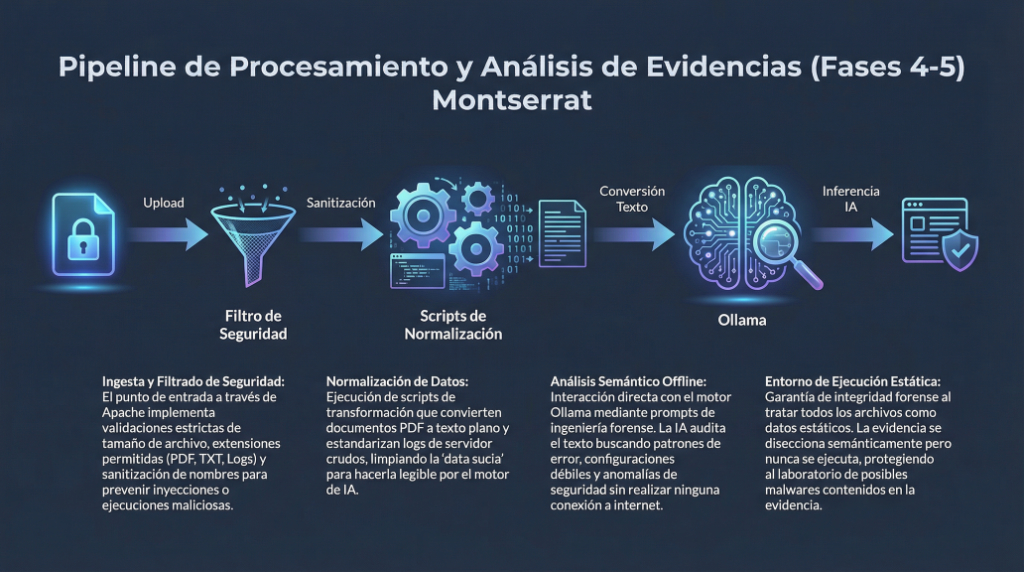
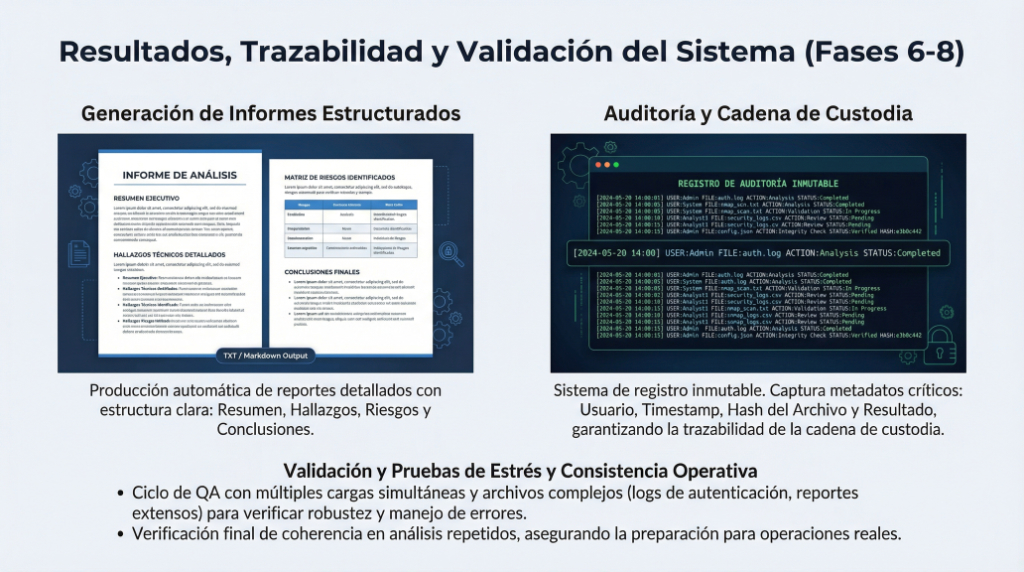
1. Introducción
En esta práctica vamos a instalar Ollama en un equipo con Windows para poder ejecutar modelos de inteligencia artificial de forma local.
Ollama permite descargar y ejecutar modelos como Llama, Qwen, Mistral u otros modelos compatibles directamente en nuestro ordenador, sin depender necesariamente de servicios externos.
Esto es especialmente interesante en clase porque nos permite trabajar conceptos como:
- Inteligencia artificial local.
- Modelos de lenguaje.
- Uso de la terminal.
- Consumo de CPU, RAM y GPU.
- Servicios accesibles desde red local.
- Integración con herramientas como Open WebUI, OpenCode o aplicaciones propias.
2. Requisitos previos
Para realizar esta práctica necesitaremos:
- Un equipo con Windows 10 o Windows 11.
- Conexión a Internet.
- Permisos para instalar programas.
- PowerShell o Terminal de Windows.
- Espacio suficiente en disco para descargar modelos.
Según la página oficial de Ollama, la versión para Windows requiere Windows 10 o posterior.
3. ¿Qué vamos a instalar?
Vamos a instalar:
Ollama para WindowsUna vez instalado, podremos ejecutar comandos como:
ollama --version
ollama pull llama3.1:8b
ollama run llama3.1:8bPaso 1. Descargar Ollama para Windows
Entramos en la página oficial de descarga de Ollama:
https://ollama.com/download/windowsEn la página oficial aparece la opción de descarga para Windows y también una instalación mediante PowerShell.
Podemos instalarlo de dos formas:
Opción A: Instalación con instalador gráfico
Esta es la opción más sencilla para alumnos que empiezan.
- Entramos en la web oficial de Ollama.
- Seleccionamos la versión de Windows.
- Descargamos el instalador.
- Ejecutamos el archivo descargado.
- Seguimos el asistente de instalación.
Cuando termine, Ollama debería quedar instalado en el sistema.
Opción B: Instalación desde PowerShell
También podemos instalar Ollama usando PowerShell.
Abrimos PowerShell y ejecutamos:
irm https://ollama.com/install.ps1 | iexEste comando aparece actualmente en la página oficial de descarga de Ollama para Windows.
Paso 2. Comprobar que Ollama está instalado
Abrimos una terminal de PowerShell y ejecutamos:
ollama --versionSi todo está correcto, veremos una salida parecida a esta:
ollama version x.x.xLa versión puede cambiar según el momento en el que se instale.
Paso 3. Comprobar que el servicio responde
Ollama funciona como una aplicación/servicio local que escucha normalmente en el puerto:
11434Podemos comprobarlo con:
curl http://localhost:11434/api/tagsSi todavía no tenemos modelos instalados, puede aparecer una lista vacía o una respuesta JSON sin modelos.
Ejemplo aproximado:
{
"models": []
}Paso 4. Descargar un primer modelo
Ahora vamos a descargar un modelo pequeño o mediano para probar.
Para empezar podemos usar:
ollama pull llama3.1:8bTambién podríamos usar un modelo orientado a programación, por ejemplo:
ollama pull qwen2.5-coder:7bLa descarga puede tardar varios minutos, dependiendo de la conexión a Internet y del tamaño del modelo.
Paso 5. Ejecutar un modelo
Una vez descargado el modelo, podemos ejecutarlo con:
ollama run llama3.1:8bAparecerá un prompt interactivo donde podremos escribir preguntas.
Por ejemplo:
>>> Explícame qué es una dirección IP como si fuera para un alumno de primero de ASIR.Ollama responderá usando el modelo cargado en local.
Para salir del chat podemos escribir:
/byePaso 6. Ver los modelos instalados
Para ver qué modelos tenemos descargados:
ollama listLa salida será parecida a:
NAME ID SIZE MODIFIED
llama3.1:8b xxxxxxxx 4.7 GB ...
qwen2.5-coder:7b xxxxxxxx 4.7 GB ...Paso 7. Ver qué modelos están cargados en memoria
Este paso es importante, especialmente si el ordenador también se usa para jugar, editar vídeo o realizar tareas pesadas.
Ejecutamos:
ollama psEste comando muestra los modelos que están cargados en ese momento.
Ejemplo:
NAME ID SIZE PROCESSOR UNTIL
llama3.1:8b xxxxxxxx 4.7 GB 100% GPU 4 minutes from nowPaso 8. Detener un modelo cargado
Si queremos liberar memoria, podemos detener un modelo con:
ollama stop llama3.1:8bO, si estamos usando otro modelo:
ollama stop qwen2.5-coder:7bEsto es útil para liberar RAM o VRAM de la tarjeta gráfica.
Paso 9. Borrar un modelo
Si queremos eliminar un modelo descargado para liberar espacio en disco:
ollama rm llama3.1:8bDespués podemos comprobar de nuevo:
ollama listPaso 10. Probar Ollama desde el navegador
Podemos abrir en el navegador:
http://localhost:11434También podemos probar directamente la API:
http://localhost:11434/api/tagsEl endpoint /api/tags permite comprobar los modelos disponibles en la instalación local.
Paso 11. Crear una petición a la API de Ollama
Ollama no solo sirve para usar modelos desde terminal. También podemos hacer peticiones HTTP a su API local.
Ejemplo desde PowerShell:
curl http://localhost:11434/api/generate `
-Method POST `
-Body '{"model":"llama3.1:8b","prompt":"Explica qué es Linux en pocas palabras.","stream":false}' `
-ContentType "application/json"Esto nos devolverá una respuesta en formato JSON.
Paso 12. Configurar Ollama para acceder desde otro equipo de la red
Por defecto, Ollama suele estar pensado para usarse desde el propio equipo. Si queremos acceder desde otro ordenador de la red local, por ejemplo desde un portátil, podemos configurar la variable de entorno:
OLLAMA_HOSTLa documentación oficial de Ollama indica que en Windows las variables de entorno se pueden configurar desde las opciones de entorno del usuario o del sistema. Para ello recomienda cerrar primero Ollama desde la barra de tareas, abrir la configuración de variables de entorno, crear o editar la variable correspondiente y volver a iniciar Ollama.
Configuración recomendada para red local
Creamos la variable:
OLLAMA_HOSTCon el valor:
0.0.0.0:11434También se puede hacer desde PowerShell como administrador:
setx OLLAMA_HOST "0.0.0.0:11434" /MDespués debemos cerrar Ollama y volver a abrirlo, o reiniciar el equipo.
Paso 13. Abrir el puerto en el firewall de Windows
Si queremos acceder a Ollama desde otro ordenador de la misma red, puede ser necesario abrir el puerto 11434.
Abrimos PowerShell como administrador y ejecutamos:
New-NetFirewallRule `
-DisplayName "Ollama 11434" `
-Direction Inbound `
-Protocol TCP `
-LocalPort 11434 `
-Action AllowPaso 14. Averiguar la IP del equipo Windows
En el equipo donde está instalado Ollama ejecutamos:
ipconfigBuscamos la dirección IPv4 de la tarjeta de red que estamos usando.
Ejemplo:
Dirección IPv4. . . . . . . . . . . . . . : 192.168.1.50En este ejemplo, la IP del equipo sería:
192.168.1.50Paso 15. Probar Ollama desde otro ordenador
Desde otro equipo de la misma red, por ejemplo un portátil, probamos:
curl http://192.168.1.50:11434/api/tagsCambiando 192.168.1.50 por la IP real del equipo Windows.
Si todo está correcto, veremos la lista de modelos disponibles.
Paso 16. Conectar Open WebUI u otra herramienta
Si instalamos una interfaz web como Open WebUI, podremos conectarla a la dirección del servidor Ollama.
Si Open WebUI está en el mismo equipo:
http://localhost:11434Si Open WebUI está en otro ordenador de la red:
http://192.168.1.50:11434Paso 17. Recomendaciones de modelos para empezar
Para equipos normales:
ollama pull llama3.1:8b
ollama pull qwen2.5-coder:7bPara equipos con buena GPU:
ollama pull qwen2.5-coder:14b
ollama pull qwen3:14bPara programación:
ollama run qwen2.5-coder:7bO, si el equipo tiene más potencia:
ollama run qwen2.5-coder:14bPara uso general:
ollama run llama3.1:8bPaso 18. Buenas prácticas si el equipo también se usa para jugar
Si el ordenador tiene una tarjeta gráfica potente y también se usa para jugar, conviene tener cuidado.
Ollama puede usar:
- RAM.
- CPU.
- GPU.
- VRAM de la tarjeta gráfica.
- Disco.
Instalar Ollama no debería reducir el rendimiento de los juegos por sí solo. El problema aparece cuando tenemos un modelo cargado mientras jugamos.
Antes de jugar podemos comprobar:
ollama psSi aparece algún modelo cargado, podemos detenerlo:
ollama stop nombre_del_modeloPor ejemplo:
ollama stop qwen2.5-coder:14bTambién podemos cerrar Ollama desde el icono de la bandeja del sistema.
Paso 19. Seguridad básica
No debemos exponer Ollama directamente a Internet.
Una cosa es usarlo dentro de nuestra red local y otra muy distinta dejarlo accesible públicamente desde fuera.
Recomendaciones:
- No abrir el puerto
11434en el router. - No hacer redirección de puertos hacia Ollama.
- Usarlo solo en red local.
- Si se necesita acceso remoto, usar VPN o una solución segura.
- No permitir que cualquier persona de la red use modelos grandes sin control.
Paso 20. Comandos principales de Ollama
| Acción | Comando |
|---|---|
| Ver versión | ollama --version |
| Descargar modelo | ollama pull nombre_modelo |
| Ejecutar modelo | ollama run nombre_modelo |
| Ver modelos instalados | ollama list |
| Ver modelos cargados | ollama ps |
| Detener modelo | ollama stop nombre_modelo |
| Borrar modelo | ollama rm nombre_modelo |
| Probar API local | curl http://localhost:11434/api/tags |
Actividad propuesta
Instalar Ollama en Windows, descargar un modelo, ejecutarlo y comprobar que funciona correctamente desde terminal y desde la API local.
Tareas
- Instalar Ollama en Windows.
- Comprobar la versión instalada.
- Descargar un modelo.
- Ejecutar el modelo desde terminal.
- Hacerle al modelo una pregunta técnica.
- Listar los modelos instalados.
- Comprobar qué modelos están cargados.
- Probar la API local con
curl. - Documentar el proceso con capturas.
- Explicar qué recursos del equipo consume Ollama.
Cargar modelos de ollama en el disco duro secundario
Importante:
Los modelos de Ollama pueden ocupar muchos gigabytes. En equipos con un disco principal pequeño, es recomendable guardar los modelos en un disco secundario usando la variable de entornoOLLAMA_MODELS. Así evitamos llenar la unidadC:y mantenemos el sistema operativo con espacio libre suficiente.
la forma correcta para Windows, que es mover la carpeta de modelos usando la variable OLLAMA_MODELS. También voy a incluir una alternativa con enlace simbólico, útil si ya tienes modelos descargados.Pensó durante 4s
Sí. En Windows tienes que cambiar la ubicación de los modelos con la variable de entorno OLLAMA_MODELS. Ollama indica oficialmente que esta variable sirve para elegir dónde se guardan los modelos descargados.
Por ejemplo, si quieres que los modelos estén en el disco D:, puedes crear esta carpeta:
D:\Ollama\ModelsOpción recomendada: usar OLLAMA_MODELS
1. Crea la carpeta en el disco secundario
En PowerShell:
mkdir D:\Ollama\ModelsPuedes cambiar D: por la letra real de tu disco.
2. Cierra Ollama
Antes de cambiar la ruta:
- Ve al icono de Ollama en la bandeja del sistema, junto al reloj.
- Clic derecho.
- Pulsa Quit o Salir.
También puedes cerrar el proceso desde PowerShell:
taskkill /IM ollama.exe /F3. Crea la variable de entorno
Abre PowerShell como administrador y ejecuta:
setx OLLAMA_MODELS "D:\Ollama\Models" /MEsto crea la variable a nivel de sistema.
También podrías crearla solo para tu usuario:
setx OLLAMA_MODELS "D:\Ollama\Models"Para un PC personal, yo usaría la opción con /M.
4. Reinicia Ollama
Después de crear la variable:
- Cierra todas las terminales.
- Vuelve a abrir PowerShell.
- Abre Ollama de nuevo desde el menú de inicio.
Para ir a lo seguro, reinicia Windows.
5. Comprueba que la variable existe
En una nueva ventana de PowerShell:
echo $env:OLLAMA_MODELSDebería aparecer:
D:\Ollama\Models6. Descarga un modelo de prueba
Por ejemplo:
ollama pull llama3.1:8bDespués comprueba que se han creado archivos dentro de:
D:\Ollama\ModelsSi ya tenías modelos descargados
Por defecto, Ollama suele guardar los modelos en la carpeta del usuario, dentro de:
C:\Users\TU_USUARIO\.ollamaLa documentación oficial también indica que %HOMEPATH%\.ollama contiene modelos y configuración.
Puedes moverlos así:
1. Cierra Ollama
taskkill /IM ollama.exe /F2. Copia la carpeta antigua al nuevo disco
Por ejemplo:
robocopy "$env:USERPROFILE\.ollama\models" "D:\Ollama\Models" /E3. Crea la variable OLLAMA_MODELS
setx OLLAMA_MODELS "D:\Ollama\Models" /M4. Reinicia Windows
Después prueba:
ollama listSi los modelos aparecen correctamente, ya está usando la nueva ubicación.

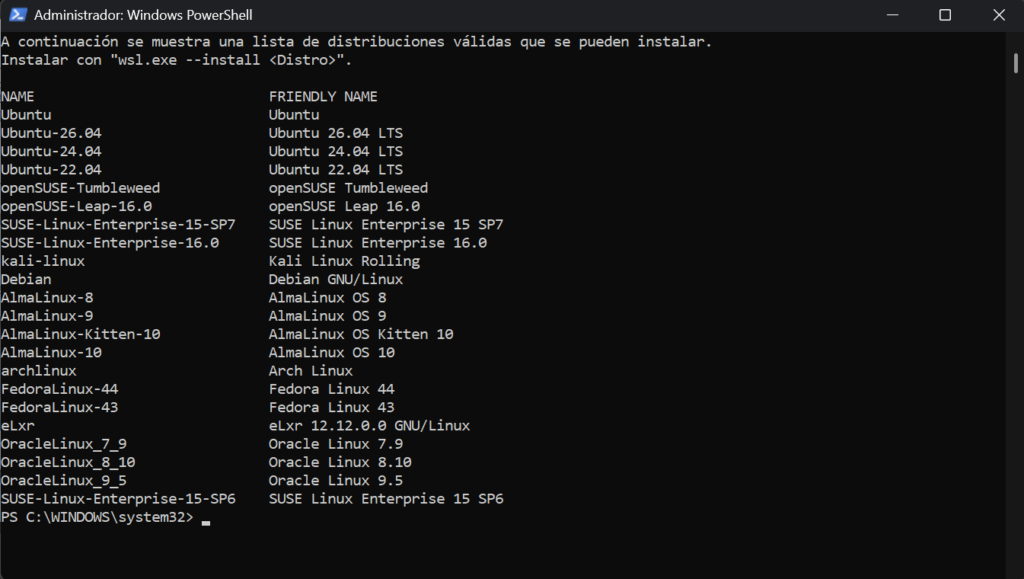

![[Reto] – Aletheia un Sistema de Auditoría y Análisis Forense Automatizado](https://laaventuradeaprender.com/wp-content/uploads/2026/01/da680bf6-26c1-4785-88c6-6cf35b86bcca.png)