OSINT (Open Source Intelligence) es el arte —y la ciencia— de obtener información a partir de fuentes públicas, sin interactuar activamente con el objetivo ni alterar sistemas.
Trabajar desde la terminal tiene varias ventajas clave:
Reproducibilidad: lo que haces hoy lo puedes repetir mañana.
Automatización: un comando hoy, un script mañana.
Mentalidad analítica: piensas en datos, no en interfaces.
Escalabilidad: una IP, cien dominios o mil subdominios.
1. AMASS – Descubrimiento de subdominios (OSINT real)
¿Qué es Amass?
Amass es una herramienta de OWASP diseñada para mapear la superficie externa de una organización, utilizando únicamente fuentes públicas cuando se trabaja en modo pasivo.
No escanea puertos, no lanza exploits. Pregunta a Internet lo que Internet ya sabe.
HTTP, visto desde el prisma del análisis forense, se convierte en un río de migas digitales. Todo lo que un usuario hace en la web —clics, formularios, cargas, descargas, redirecciones— queda reflejado en forma de peticiones y respuestas. Para un analista forense, ese flujo es una fuente de verdad incómodamente sincera.
1. HTTP desde la perspectiva del Análisis Forense
HTTP (Hypertext Transfer Protocol) es el lenguaje de comunicación entre navegadores y servidores web. En condiciones normales es un protocolo simple, sin cifrar, basado en texto plano. Esa “simplicidad” lo convierte en un objetivo fantástico para la reconstrucción forense de actividades.
¿Por qué HTTP importa en un análisis forense?
HTTP expone tres elementos cruciales:
Qué hizo un usuario Las URLs visitadas describen intención, interés y acciones concretas. Un acceso a /wp-admin/ no es lo mismo que una visita a /index.html.
Qué envió un usuario Si no hay cifrado (HTTP a secas), el analista puede ver:
campos de formularios
parámetros en la URL
cookies
cabeceras personalizadas
Son pruebas directas de actividad.
Qué devolvió el servidor Los códigos de estado (200, 404, 500…) cuentan historias:
¿Se intentó acceder a un recurso prohibido? (403)
¿Hubo intentos de escaneo? (404 repetidos)
¿Hubo redirecciones sospechosas? (3xx)
En un entorno HTTPS el contenido se cifra, pero la metadata sigue hablando: SNI, IPs de destino, tamaño de paquetes, frecuencia de conexiones.
2. Qué puede analizar un forense dentro del tráfico HTTP
Cuando el tráfico está en claro (capturas PCAP, logs de proxy, almacenamientos en disco…), un analista puede reconstruir:
Peticiones
Método usado (GET, POST, PUT…)
URL completa con parámetros
Cookies
User-Agent
Referer (muy útil para reconstruir navegación)
Origen de la petición
Respuestas
Códigos de estado
Tipo de contenido (Content-Type)
Descarga de ficheros
Redirecciones (sirven para detectar phishing o malware)
Cuerpo (Body)
Formularios enviados
Archivos subidos
Tokens
Sesiones reutilizadas
Comandos dentro de ataques (SQLi, XSS, LFI, RFI)
HTTP deja la puerta abierta a ver la anatomía completa del ataque.
3. Indicadores forenses típicos en HTTP
Un forense puede detectar patrones de ataque leyendo únicamente tráfico HTTP.
parámetros larguísimos y codificados (Base64, hex, etc.)
HTTP se convierte en un diario de guerra para quien sabe leerlo.
4. Fuentes forenses relacionadas con HTTP
PCAPs
Capturas obtenidas con Wireshark/tcpdump → reconstrucción completa de la sesión.
Logs de servidor
Apache: access.log y error.log
Nginx: access.log y error.log
IIS: logs W3C
Incluyen:
IP origen
timestamp
método
URL
código de respuesta
tamaño de respuesta
User-Agent
Logs de proxy/IDS/IPS
Squid
Suricata
Snort
Detectan patrones de ataque.
Carpetas temporales del navegador
Cuando no hay cifrado, muchos navegadores almacenaban recursos en caché → reconstrucción de contenido web visitado.
5. Qué valor aporta HTTP en un caso forense
HTTP permite:
Atribución
Qué IP hizo qué petición, cuándo, y hacia dónde.
Reconstrucción cronológica
Secuencia exacta de navegación.
Detección de actividad maliciosa
Scripts, comandos, payloads.
Derivación de intenciones
El tipo de URL buscada revela motivación y objetivos.
Prueba digital sólida
HTTP es fácil de interpretar y explicar en un informe pericial.
LAS CAPAS DE HTTP
En un recorrido típico, desde que un navegador lanza un GET hasta que el servidor responde un 200 OK, intervienen estas capas:
1. Capa de Aplicación (HTTP “de verdad”) Aquí es donde vive el propio HTTP. Todo lo que son métodos (GET, POST…), cabeceras, cookies, códigos de estado, cuerpos JSON/HTML/lo-que-sea, ocurre aquí. Es la capa donde se expresa la intención humana: “dame este recurso”, “aquí tienes mi formulario”, “acepto gzip”.
2. Capa de Transporte (TCP) HTTP clásico usa TCP, que actúa como el mensajero meticuloso: garantiza que los datos lleguen en orden, completos y sin que nadie se pierda por el camino. Aquí se negocia el 3-way handshake, se fragmentan segmentos, se controlan retransmisiones y se mantiene la conexión.
3. Capa de Red (IP) IP es la guía turística poco habladora que solo sabe entregar paquetes. Se ocupa de mover esos segmentos TCP a través de routers, saltos, rutas posibles, usando direcciones IP. No sabe nada de “GET /index.html”, solo sabe de “lleva este paquete a la 172.217.x.x”.
4. Capa de Enlace de Datos (Ethernet / Wi-Fi) Aquí estamos en el nivel de los marcos (frames), las MACs, la detección de colisiones, los canales radioeléctricos… Es la autopista física donde circulan los bits.
5. Capa Física Aquí no hay cabeceras ni protocolos nobles. Solo voltajes, pulsos, ondas, fibras, fotones. Es la capa donde HTTP desaparece por completo y solo quedan electrones corriendo nerviosos.
Ejemplo
Vamos a hacer un ejemplo muy visual, como si desmontáramos una muñeca rusa digital. Imagina que tu navegador quiere pedir:
GET /login.html HTTP/1.1 Host: ejemplo.com
Ese texto tan inocente pasa por una cadena de capas. Te lo describo como si fuese un “viaje del paquete” de arriba abajo.
1. Capa de Aplicación (HTTP)
Aquí se construye el mensaje original:
GET /login.html HTTP/1.1 Host: ejemplo.com User-Agent: Firefox Accept: text/html
Todavía no hay números de puertos, ni IPs, ni MACs. Solo intención: “dame este recurso”.
2. Capa de Transporte (TCP)
HTTP se mete dentro de un segmento TCP. Ahora aparecen cosas como:
Puerto origen: 53214
Puerto destino: 80
Número de secuencia: 45500123
Flags: PSH, ACK
Wireshark es un analizador de tráfico de red que permite capturar y examinar, en tiempo real o a través de archivos pcap, todos los paquetes que circulan por un equipo o una interfaz de red. Su potencia reside en su capacidad para mostrar cada detalle de la comunicación: protocolos, cabeceras, datos, errores y patrones internos.
Sin embargo, una captura completa suele contener miles de paquetes mezclados: peticiones web, DNS, tráfico de fondo del sistema, retransmisiones TCP, etc. Analizar todo a la vez es inviable. Para poder investigar de forma eficaz, necesitamos herramientas que nos permitan centrarnos solo en lo relevante.
Aquí es donde entran en juego los filtros de visualización.
2. ¿Qué son los filtros de Wireshark?
Un filtro en Wireshark es una expresión que permite mostrar únicamente los paquetes que cumplen una o varias condiciones. El resto de los paquetes no se eliminan: simplemente se ocultan temporalmente de la vista.
Los filtros son una forma de decirle a Wireshark:
“De entre todos estos miles de paquetes, solo quiero ver los que coincidan con esta característica concreta.”
Por ejemplo:
“Solo quiero ver peticiones GET a una web.”
“Muéstrame las cookies enviadas por el navegador.”
“Quiero ver los paquetes destinados al puerto 80.”
“Enséñame el tráfico DNS para saber qué dominios se resolvieron.”
Con esto, el análisis deja de ser caótico y se convierte en una investigación guiada.
3. ¿Cómo funcionan por dentro?
3.1. Campos de los protocolos
Wireshark entiende cada protocolo y lo descompone en campos. Por ejemplo, en HTTP podemos encontrar:
http.host
http.request.method
http.cookie
En TCP aparecen campos como:
tcp.port
tcp.flags.syn
tcp.seq
En DNS:
dns.qry.name
Cada uno de estos campos puede usarse para crear filtros.
3.2. Operadores
Para comparar esos campos con valores concretos, Wireshark utiliza operadores lógicos y relacionales:
Operador
Significado
==
Igual a
!=
Distinto
contains
El campo contiene un texto concreto
< / >
Comparación numérica
&&
AND lógico
`
!
Negación (NO)
Con estos operadores podemos crear condiciones desde sencillas hasta muy complejas.
3.3. Ejemplos básicos
http
Muestra únicamente paquetes HTTP.
http.request.method == "POST"
Filtra todas las peticiones POST (ideal para ver formularios y logins sin cifrar).
tcp.port == 80
Muestra tráfico hacia/desde el puerto 80 (HTTP en claro).
http.cookie contains "PHPSESSID"
Filtra cookies asociadas a sesiones PHP.
4. ¿Para qué sirven realmente?
Los filtros permiten:
• Analizar aplicaciones web en PHP
Ver cómo un navegador solicita index.php, cómo envía credenciales por POST o cómo recibe una cookie de sesión.
• Depurar problemas
Identificar errores HTTP, pérdidas de paquetes, retransmisiones TCP o peticiones repetidas.
• Seguir el flujo de un usuario
Reconstruir la secuencia de navegación: qué URL pidió, cuándo inició sesión y qué recursos cargó la página.
• Detectar configuraciones inseguras
Tráfico HTTP en claro, cookies sin atributos de seguridad, peticiones POST sin cifrar…
• Aprender el funcionamiento interno de la red
DNS, ARP, TLS, TCP handshake y otros mecanismos que normalmente pasan desapercibidos.
5. Tipos de filtros en Wireshark
Wireshark tiene dos categorías (aunque muchos alumnos las confunden al principio):
1. Filtros de captura (Capture Filters)
Se aplican antes de capturar y limitan qué paquetes se guardan en el archivo. Tienen sintaxis estilo BPF (más escueta): Ejemplo:
port 80
host 192.168.1.100
2. Filtros de visualización (Display Filters)
Se aplican después de capturar y permiten analizar sin perder nada. Son los que se usan el 99% del tiempo en clase:
Los filtros son la herramienta fundamental para convertir una captura de tráfico en bruto en una historia comprensible. Permiten investigar, aprender, depurar y entender cómo se comportan las aplicaciones web y los protocolos de red.
Dominar los filtros equivale a dominar Wireshark.
Filtros básicos pero muy visuales
1. Filtrar por HTTP en claro Cuando trabajan con un hosting sin HTTPS o usando HTTP local:
http
Muestra peticiones GET, POST, cabeceras, parámetros… el caramelo didáctico ideal.
2. Solo peticiones GET
http.request.method == "GET"
Sirve para ver qué recursos pide el navegador: imágenes, JS, CSS, el index.php.
3. Solo peticiones POST (login, formularios)
http.request.method == "POST"
Perfecto para mostrar cómo se enviarían credenciales sin cifrar. Nada despierta conciencias como ver un usuario y contraseña en texto plano.
Filtros para cazar PHP
4. Peticiones explícitas a archivos PHP
http.request.uri contains ".php"
Puedes ver exactamente qué scripts se llaman: login.php, insert.php, update.php.
5. Extraer cookies (sesiones PHP)
http.cookie
Llega el momento «¿ves esto? Esto es tu sesión… y si te la robo, te convierto en ti».
6. Ver el PHPSESSID en tráfico no cifrado
http.cookie contains "PHPSESSID"
Es el filtro dramático: el espíritu del session hijacking entra en clase.
Cuando todo va cifrado (HTTPS)
La gente suele pensar “si está cifrado, no veo nada”, pero sí hay cosas interesantes:
7. Filtrar solo TLS/SSL
tls
8. Ver el SNI (qué dominio está visitando el cliente)
tls.handshake.extensions_server_name
SNI revela dominios incluso aunque el contenido esté cifrado. Muy útil para explicación OSINT.
9. Ver el handshake TLS
tls.handshake
Para explicar versiones de TLS, cipher suites, certificados…
Filtros orientados al servidor web
10. Filtrar por puerto
tcp.port == 80 || tcp.port == 443
Básico pero efectivo para centrar el tráfico.
11. Filtrar errores HTTP
http.response.code >= 400
Se ven los 404, 403, 500… Ideal cuando tus alumnos han roto algo sin querer.
12. Ver solo respuestas 200 (todas bien)
http.response.code == 200
Filtros para mostrar problemas reales
13. Retransmisiones TCP (problemas de red)
tcp.analysis.retransmission
Traduce “la red no es perfecta, observad estas repeticiones”.
14. Paquetes fuera de orden
tcp.analysis.out_of_order
15. Flujo lento o paquetes perdidos
tcp.analysis.lost_segment
Filtros de capas bajas (para dar color a la clase)
16. Filtrar ARP
arp
Es como ver el vecindario de máquinas preguntándose mutuamente “¿quién eres?”.
17. Filtrar DNS
dns
Verán cada dominio que consulta el navegador antes siquiera de entrar al PHP.
Un combo que siempre triunfa en clase
Ver solo: peticiones POST + tráfico HTTP + mostrar cookies Sirve para simular un login vulnerable:
http.request.method == "POST" && http.cookie
Y si están usando HTTPS pero quieres que entiendan lo que no pueden ver:
tls && http
No aparece nada HTTP, y eso invita al clásico «¿ves? por esto existe HTTPS».
Práctica: Análisis de Tráfico HTTP con Wireshark en una Web Vulnerable
Caso práctico: testphp.vulnweb.com
1. Introducción
En esta práctica aprenderás a utilizar Wireshark para analizar el tráfico HTTP generado al navegar por una aplicación web vulnerable. El objetivo es comprender cómo viajan las peticiones y respuestas en una web sin cifrado, identificar parámetros, observar cabeceras, analizar formularios y cookies de sesión, y entender los riesgos de seguridad asociados.
La web utilizada es:
http://testphp.vulnweb.com/
Este sitio es un entorno público y autorizado para prácticas de ciberseguridad ofrecido por Acunetix, por lo que su uso es completamente legal con fines académicos.
2. Objetivos de la práctica
Al finalizar la actividad, deberás ser capaz de:
Capturar tráfico HTTP real con Wireshark.
Aplicar filtros para aislar información concreta.
Analizar peticiones GET y POST.
Identificar parámetros, rutas internas y patrones de navegación.
Localizar cookies y sesiones enviadas en texto claro.
Comprender los riesgos de enviar credenciales por HTTP.
3. Procedimiento
3.1. Preparación
Abre Wireshark.
Selecciona la interfaz de red que utilices para navegar por Internet.
Inicia la captura de paquetes.
Abre el navegador y visita:
http://testphp.vulnweb.com/
Navega por distintas secciones: categorías, productos, artista, carrito…
Accede al formulario de login e introduce cualquier usuario y contraseña (fallará siempre, es parte del diseño).
Realiza varias acciones para generar tráfico suficiente.
Regresa a Wireshark y detén la captura.
4. Análisis guiado en Wireshark
A continuación aplicarás varios filtros y analizarás lo que ocurre en cada caso.
4.1. Visualizar únicamente tráfico HTTP
Filtro:
http
Qué debes observar:
Todas las peticiones realizadas al servidor.
Rutas como /index.php, /listproducts.php, /product.php, etc.
Imágenes, scripts y otros recursos solicitados.
Ejemplo típico que deberías encontrar:
GET /listproducts.php?cat=1 HTTP/1.1
Host: testphp.vulnweb.com
4.2. Listar únicamente peticiones GET
Filtro:
http.request.method == "GET"
Observa cómo la web utiliza parámetros en la URL. Ejemplos que verás:
GET /artist.php?artist=4
GET /product.php?pic=3
GET /listproducts.php?cat=2
Esto permite mapear la estructura del sitio.
4.3. Detectar peticiones con parámetros
Filtro:
http.request.uri contains "="
Este filtro muestra exclusivamente peticiones con parámetros GET.
Ejemplos esperados:
GET /shoppingcart.php?add=2
GET /login.php?test=1
Fíjate en cómo la información viaja en texto plano.
4.4. Analizar el login (peticiones POST)
En la web, introduce un usuario y contraseña en el formulario.
Filtro:
http.request.method == "POST"
Debes encontrar una petición similar a:
POST /userinfo.php HTTP/1.1
Content-Type: application/x-www-form-urlencoded
uname=prueba&pass=1234
Reflexiona sobre el riesgo de enviar credenciales por HTTP sin cifrar.
4.5. Visualizar cookies y sesiones
Filtro:
http.cookie
Deberías ver algo como:
Cookie: PHPSESSID=8d6v93h3k8a...
Esto confirma que la sesión también viaja sin protección alguna.
4.6. Encontrar errores en la web
Filtro:
http.response.code >= 400
Este filtro permite localizar:
Páginas no encontradas (404)
Errores internos (500)
Accesos no permitidos (403)
Esto ayuda a entender la estructura interna del sitio.
4.7. Localizar recursos concretos: imágenes, JS y CSS
Para analizar recursos específicos:
Imágenes (JPG):
http.request.uri contains ".jpg"
Scripts:
http.request.uri contains ".js"
Hojas de estilo:
http.request.uri contains ".css"
Permite reconstruir exactamente todo lo que carga el navegador.
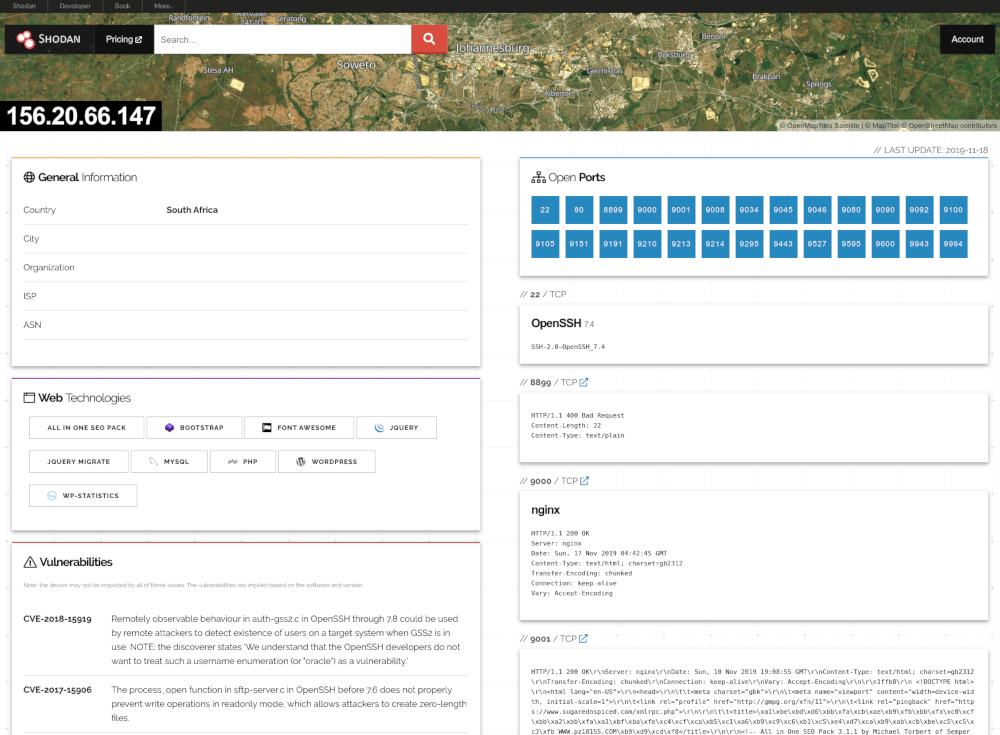
Operación Nostromo: búsqueda de dispositivos comprometidos antes de que “algo” despierte…
La nave USCSS Nostromo ha recibido una transmisión automática desde un sistema remoto. No se sabe si es una llamada de socorro… o una advertencia. La compañía ha encomendado al Equipo de Investigación (tus alumnos) usar Shodan para rastrear:
Señales de dispositivos expuestos
Orígenes de la transmisión
Infraestructura del sistema remoto
Posibles vectores de intrusión
La misión: analizar patrones, encontrar conexiones y trazar el mapa de un “nido” digital escondido.
La actividad se divide en 3 fases, cada una con un objetivo claro y un filtro de Shodan.
Escanea infraestructura global, con foco extra en certificados SSL/TLS, puertos, hosts — útil para mapear superficie de ataque de forma sistemática. 5 Minute Breach+2We Live Security+2
ZoomEye
Similar a Shodan; ampliamente usada fuera del “mainstream” occidental. Puede servir para comparar visiones distintas del Internet expuesto. MarPoint+2SecurityVision.ru+2
BinaryEdge
Permite monitorear servicios, puertos abiertos, SSL, accesos remotos — y recibir alertas. Buena opción para vigilancia continua o auditorías periódicas. We Live Security+2LearnHub+2
Fofa
Ofrece sintaxis de búsqueda avanzada, lo que facilita búsquedas muy específicas (por puerto, servicio, sello de software, etc.). Puede servir bien para ejercicios dirigidos. We Live Security+1
GreyNoise
No es exactamente un “scanner” de dispositivos, sino más bien un filtro de ruido: ayuda a clasificar qué direcciones/IPs simplemente están haciendo escaneos automáticos masivos (ruido) frente a actividad potencialmente relevante. Útil para refinar resultados (filtrar falsos positivos). We Live Security+2LearnHub+2
Netlas
Plataforma más reciente, pensada para descubrimiento y monitorización global de “activos conectados”. Puede ser útil si buscas comparar con herramientas más consolidadas. SecurityVision.ru+2Netlas+2
⚠️ Cosas a tener en cuenta
Ninguna herramienta cubre todos los dispositivos — pueden faltar muchos servicios expuestos, por bloqueo, firewalls, NAT, técnicas de evasión.
Los datos recogidos (puertos, software, banners) pueden estar desactualizados o ser engañosos: muchas veces los sistemas cambian o los banners son falsos.
Uso de herramientas externas implica responsabilidad ética — incluso si lo haces con fines académicos, siempre debe mantenerse respeto por la privacidad y normas legales.
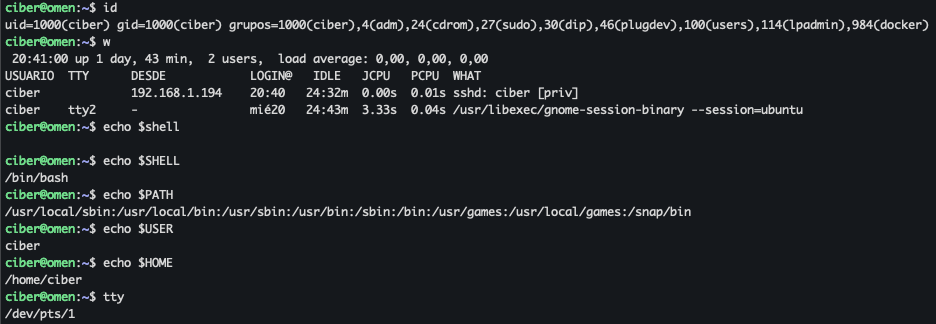
El equivalente digital de mirarse al espejo. Muestra el usuario efectivo que está ejecutando el comando. Perfecto para explicar la diferencia entre:
usuario real (el que inicia sesión),
usuario efectivo (el que el sistema usa para permisos, especialmente tras un sudo).
id
Un pequeño radiotelescopio hacia tu identidad numérica. Muestra:
UID (identificador del usuario)
GID (grupo principal)
grupos secundarios Es una forma directa de ver permisos y roles dentro del sistema. Ideal para ejercicios de administración y forense.
who / w / users
El “quién está ahora mismo en la nave”. Sirve para ver sesiones activas y cómo han entrado:
tty
pts (sesiones remotas)
SSH
tiempo conectado
En ciberseguridad es una herramienta rápida para detectar conexiones sospechosas.
env
El baúl entero de variables de entorno. Aquí viven cosas como:
$USER
$HOME
$SHELL
$PATH
Además permite explicar a los alumnos por qué una aplicación “sabe” dónde buscar binarios o dónde está su carpeta de configuración.
echo $USER
Una forma simple de leer la variable que indica el nombre del usuario que ha iniciado sesión. Comparar whoami vs $USER es didáctico: $USER → quien inició sesión whoami → usuario efectivo (útil para mostrar cómo sudo cambia el contexto)
echo $HOME
Viene genial para scripts o explicaciones sobre la organización del sistema. Muestra la ruta al directorio personal, que siempre es sagrado en Linux.
echo $SHELL
Permite enseñar la diferencia entre bash, zsh, fish… Ideal para que entiendan por qué su terminal “se comporta raro” tras instalar algo.
hostname
La identidad pública del sistema en la red. Junto con hostname -I, sirve para explicar la distinción entre:
identidad del equipo,
interfaces,
direcciones IP que usa para comunicarse.
logname
La versión más purista de “quién inició esta sesión”, incluso si has hecho un su o un sudo. Muy útil en prácticas de forense porque te permite reconstruir acciones de usuarios.
tty
Muestra el dispositivo de terminal actual. En remoto se verá algo como /dev/pts/1. Perfecto para entender:
sesiones locales,
sesiones remotas,
multiplexación de terminales.
ps aux | grep $USER
Una puerta a ver “qué está ejecutando realmente tu identidad”. A los alumnos les ayuda a comprender procesos, permisos, señales y contextos.
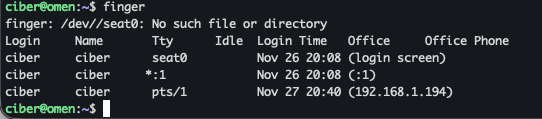
finger (si lo instalas)
Pinta un pequeño perfil del usuario:
shell
home
nombre real
Antiguo pero didáctico como pocas cosas.
Actividad: “¿Quién eres en esta máquina?” – Identidad y sesiones en Linux
Imagina que el sistema es una estación espacial. Cada alumno entra por una compuerta distinta, a veces cambia de traje (sudo), y el objetivo es reconstruir quién hizo qué.
Todo ocurre en un Ubuntu normal.
FASE 1 — Identidad básica
Ejecuta:
whoami
echo $USER
id
logname
Descubrir que el sistema te reconoce por varias “capas”.
Explicación:
whoami → usuario efectivo.
$USER → usuario que inició sesión.
id → UID, GID, grupos.
logname → el user original aunque hayan hecho su.
Pequeño reto: Pídeles que intenten entender por qué sudo whoami devuelve root, pero echo $USER sigue mostrando su usuario normal.
FASE 2 — Dónde están realmente
Ejecutar
pwd
echo $HOME
echo $SHELL
tty
Esto muestra:
dónde están,
cuál es su shell,
qué terminal están usando (local, SSH, pts…).
Ejercicio: Compartir un terminal local (tty1) con una sesión SSH
FASE 3 — Quién más está en la nave
Ahora miramos el estado de la estación:
who
w
users
hostname
hostname -I
Objetivo: identificar todas las sesiones activas. Puedes entrar desde otra máquina para ver “un intruso”.
Mini-misión: Que usen who para averiguar:
quién está conectado,
desde qué terminal,
desde qué IP si es SSH,
desde cuándo.
Esto introduce sin ruido en análisis forense real.
FASE 4 — Cambio de identidad
sudo -i
whoami
echo $USER
id
logname
tty
Aquí ocurre la magia:
whoami → root
$USER → su usuario original
logname → quien realmente abrió la sesión
tty → la misma porque no abren una nueva
FASE 5 — Ver qué hace cada identidad
En otra terminal, que ejecuten:
ps aux | grep $USER
ps aux | grep root
Fijate que root suele llevar servicios, demonios, etc.
FASE 6 — Prueba forense
Prueba a ejecutar con un usuario un comando secreto en su sesión, por ejemplo:
Google Hacking es una técnica de búsqueda utilizada para encontrar información específica en los motores de búsqueda, como Google.
[!NOTA] Este tipo de búsquedas no son invasivas, ya que no hacen peticiones al servidor del objetivo, por lo que podemos utilizar estas técnicas libremente.
La Google Hacking Database (GHDB) es una colección de comandos de búsqueda de Google y técnicas de búsqueda avanzadas que se utilizan para encontrar información que puede ser útil en la realización de pruebas de penetración y en la investigación de seguridad.
La GHDB fue creada por Johnny Long, un experto en seguridad informática, y es mantenida por una comunidad de profesionales de la seguridad informática. La GHDB contiene miles de comandos de búsqueda de Google y técnicas de búsqueda avanzadas que se utilizan para encontrar información confidencial, como contraseñas, información de inicio de sesión, archivos de configuración, archivos de registro y más.
Los comandos de búsqueda de Google en la GHDB se organizan en categorías, como «Vulnerabilities», «Files containing passwords» y «Sensitive Directories». Cada comando de búsqueda viene con una descripción detallada de lo que busca y cómo se puede utilizar.
La GHDB se utiliza comúnmente en pruebas de penetración y en la investigación de seguridad para buscar información confidencial que puede ser utilizada en un ataque. Es importante tener en cuenta que la GHDB debe utilizarse con precaución y solo con el permiso del propietario del sitio web o de la red que se está probando. También es importante asegurarse de que cualquier información confidencial descubierta se informe al propietario del sitio web o a las autoridades apropiadas.
Google Dorks
Los Google Dorks son combinaciones específicas de palabras o frases que se usan para realizar búsquedas avanzadas en Google y obtener resultados que no se pueden obtener mediante una búsqueda normal.
Es importante tener en cuenta que los Google Dorks no son herramientas de hacking en sí mismas, sino una técnica para realizar búsquedas avanzadas en Google. Sin embargo, los Google Dorks pueden ser utilizados por los hackers para encontrar información sensible que puede ser utilizada en ataques posteriores. Por lo tanto, se recomienda utilizar los Google Dorks de manera responsable y con fines éticos, especialmente si se utilizan en el campo de la seguridad informática.
Operador
Descripción
Ejemplo
Explicación del ejemplo
site:
Limita resultados a un dominio específico.
site:example.com
Encuentra todas las páginas accesibles en example.com.
inurl:
Busca un término dentro de la URL.
inurl:login
Localiza páginas de inicio de sesión.
filetype:
Filtra por tipo de archivo.
filetype:pdf
Encuentra documentos PDF descargables.
intitle:
Busca un término en el título de la página.
intitle:"confidential report"
Busca documentos titulados “informe confidencial” o similares.
intext: / inbody:
Busca dentro del cuerpo del texto.
intext:"password reset"
Encuentra páginas con “restablecimiento de contraseña”.
cache:
Muestra la versión en caché de Google.
cache:example.com
Ve contenido antiguo o previo de example.com.
link:
Encuentra páginas que enlazan a otra.
link:example.com
Muestra webs que tienen enlaces hacia example.com.
related:
Encuentra páginas parecidas a otra.
related:example.com
Descubre sitios similares a example.com.
info:
Muestra información básica sobre un sitio.
info:example.com
Título, descripción y datos del sitio.
define:
Busca definiciones de una palabra.
define:phishing
Obtiene la definición de phishing.
numrange:
Busca números dentro de un rango.
site:example.com numrange:1000-2000
Busca páginas de ese dominio con números entre 1000 y 2000.
allintext:
Todas las palabras deben aparecer en el texto.
allintext:admin password reset
Localiza páginas que contienen ambas palabras.
allinurl:
Todas las palabras deben aparecer en la URL.
allinurl:admin panel
Busca URLs con “admin” y “panel”.
allintitle:
Todas las palabras deben estar en el título.
allintitle:confidential report 2023
Busca títulos con esas tres palabras.
AND
Exige que todos los términos aparezcan.
site:example.com AND (inurl:admin OR inurl:login)
Busca paneles admin o login en example.com.
OR
Acepta cualquiera de los términos.
"linux" OR "ubuntu" OR "debian"
Busca páginas que mencionen cualquiera de esos sistemas.
NOT
Excluye resultados con un término.
site:bank.com NOT inurl:login
Excluye las páginas de login.
* (comodín)
Sustituye cualquier palabra/caracter.
site:socialnetwork.com filetype:pdf user* manual
Encuentra “user guide”, “user manual”, etc.
.. (rango)
Busca valores dentro de un intervalo numérico.
site:ecommerce.com "price" 100..500
Busca productos entre 100 y 500.
"" (comillas)
Busca coincidencia exacta.
"information security policy"
Busca esa frase exacta.
- (menos)
Excluye un término concreto.
site:news.com -inurl:sports
Noticias sin resultados deportivos.
Ejemplos de uso:
Google Dork
Descripción
intitle:"Index of" password.txt
Muestra directorios que contienen archivos llamados “password.txt”.
intitle:"Index of" /admin
Muestra directorios de administración.
filetype:xls inurl:"email.xls"
Muestra listados de emails expuestos.
inurl:"login" site:example.com
Encuentra páginas de inicio de sesión en un sitio concreto.
filetype:log inurl:"password.log"
Encuentra logs cuyo nombre contiene “password”.
intitle:index.of id_rsa -id_rsa.pub
Encuentra claves privadas SSH expuestas.
site:.gov intitle:"secret" filetype:pdf
Encuentra archivos PDF gubernamentales expuestos.
intext:"Welcome to phpMyAdmin"
Encuentra instalaciones de phpMyAdmin accesibles.
inurl:/wp-content/uploads/ filetype:pdf
Busca PDFs dentro de uploads de WordPress.
intitle:"Index of" /backup
Encuentra directorios de backups accesibles.
site:example.com ext:sql
Busca bases de datos SQL en ese dominio.
intitle:"index of" "database.sql"
Busca archivos SQL expuestos.
intitle:"SQL Injection" site:example.com
Encuentra páginas del sitio que mencionan SQL Injection.
Muestra el directorio actual del servidor (grave exposición).
intitle:"index of" intext:web.config
Directorios indexados con web.config.
filetype:reg reg HKEY_CURRENT_USER username
Busca archivos de registro que contengan “username”.
inurl:"ViewerFrame?Mode="
Encuentra cámaras accesibles por ese visor.
intext:"powered by vBulletin"
Encuentra webs que usan vBulletin.
intitle:"index of" inurl:ftp
FTPs accesibles de forma pública.
intitle:"index of" "WhatsAppDB.csv"
Directorios con bases de datos de WhatsApp expuestas.
filetype:env intext:APP_ENV
Busca archivos .env con info sensible.
inurl:"/phpinfo.php"
Encuentra páginas phpinfo expuestas.
intitle:"index of" intext:sftp-config.json
Directorios con configuraciones SFTP.
A continuación se muestran algunos ejemplos comunes de Google Dorks; para obtener más ejemplos, consulte la Google Hacking Database:
Encontrar páginas de inicio de sesión:
site:example.com inurl:login
site:example.com (inurl:login OR inurl:admin)
Identificar de archivos expuestos:
site:example.com filetype:pdf
site:example.com (filetype:xls OR filetype:docx)
Descubrir archivos de configuración:
site:example.com inurl:config.php
site:example.com (ext:conf OR ext:cnf)(busca extensiones comúnmente utilizadas para archivos de configuración)
Localizar copias de seguridad de bases de datos:
site:example.com inurl:backup
site:example.com filetype:sql
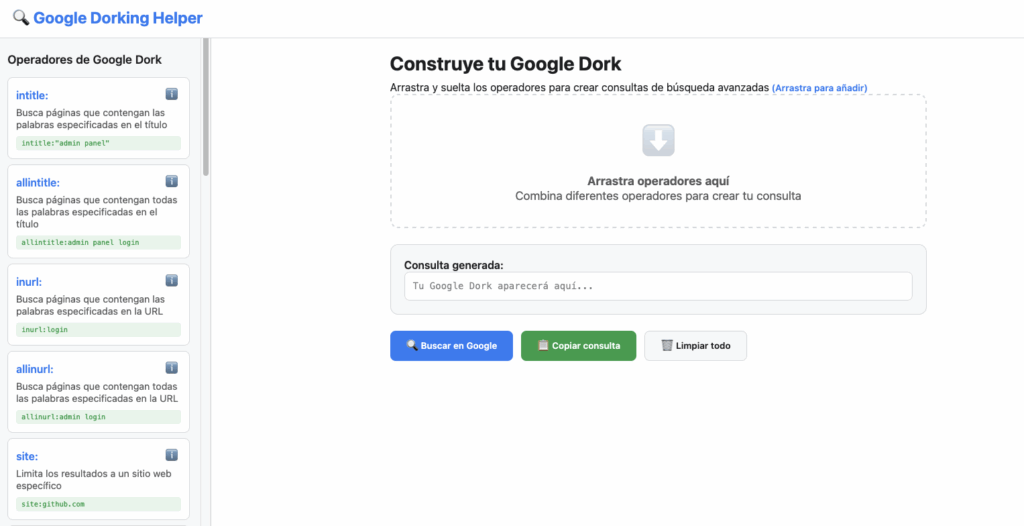
Automatización: Google Dorking Helper
Podemos automatizar la generación de Google Dorks con herramientas cómo Google Dorking Helper, que nos permite arrastrar operadores para ir construyendo nuestro dork. Una vez que lo hemos generado podemos darle directamente a «Buscar en Google» para abrirlo en el navegador.
CASO DE USO: Detectando archivos expuestos en un dominio con Google Dorks
Imagina que quieres comprobar example.com (o cualquier dominio propio de prácticas) expone algún archivo de configuración, backups o bases de datos de forma accidental.
1. Entramos en GoogleDorks (la web recopilatoria)
Hay varias webs que recopilan dorks ya probados, como:
Exploit-DB Google Hacking Database (GHDB)
googledorks.com
publicdorks repos en GitHub
Las usan solo como referencia, nunca para atacar sistemas reales.
2. Elegimos un dork útil para auditoría
Por ejemplo, un clásico para detectar bases de datos expuestas:
site:example.com ext:sql
Este dork busca archivos .sql accesibles desde el navegador.
3. Lo probamos en Google
En un entorno de práctica (por ejemplo, un dominio controlado por el aula), lo que vemos es algo así:
/backup/database.sql
/db/export_2023.sql
/old/backup.sql
Si Google muestra entradas similares, quiere decir que los archivos son accesibles públicamente y están indexados. Eso convierte una simple curiosidad en un aviso rojo.
4. Interpretamos el resultado
Les explicas a los alumnos:
Si Google lo indexa, quiere decir que el servidor lo publica sin restricciones
Esto no es hacking activo; es lectura pública de lo que ya está expuesto.
Archivos .sql suelen contener tablas, usuarios, hashes de contraseña, etc.
Aquí entra tu guiño filosófico habitual: el buscador es como un telescopio enorme; si apuntas a una ventana con luz encendida, no estás entrando en la casa, solo ves lo que ellos dejaron abierto.
5. Propones medidas de mitigación
Esto les ayuda a cerrar el círculo mental del auditor:
Sacar carpetas de backup fuera del public_html o document root.
Configurar .htaccess o reglas en el servidor que impidan servir .sql, .env, .conf…
Quitar directorios listados (“Index of”).
Desactivar el autoindex en Apache/Nginx.
Aplicar permisos adecuados del sistema.
6. Otro ejemplo más avanzado desde GoogleDorks.com
En GoogleDorks encuentran típicamente entradas como:
intitle:"index of" /backup
Lo combinan con su dominio de pruebas:
site:example.com intitle:"index of" /backup
Resultado (en un entorno controlado): Google podría mostrar un listado de backups accesibles.
Aquí se ve el poder del dork: localizar un error de configuración sin escaneo activo ni intrusiones.
CASO DE USO: “Ventanas Abiertas en la Red”
La pantalla parpadea. No estás hackeando nada. Solo observas. Lo que Google muestra es lo que ya estaba ahí, flotando en la superficie como un mensaje en una botella. Elliot lo explica con su serenidad afilada:
«El buscador es un espejo gigante. Refleja lo que los servidores enseñan sin darse cuenta. Si sabes dónde mirar, puedes encontrar más de lo que cualquier administrador admitiría».
Elliot abre una pestaña, teclea despacio, casi ritual:
site:example.com ext:sql
Darlene levanta una ceja. «¿Ya? ¿Así de simple?»
Él asiente. «El truco nunca es forzar la cerradura; es descubrir que la puerta estaba abierta desde siempre».
La búsqueda devuelve un par de enlaces inocentes: /backup/database.sql, /old/export_2022.sql. Como si fuera normal. Como si no contuvieran medio corazón de ese servidor, latido a latido.
Darlene sonríe, ese tipo de sonrisa que solo aparece cuando ve un fallo que podría haberse evitado con dos minutos de atención. «Archivos SQL, backups… Esto es como dejar el diario íntimo abierto en medio de la calle», murmura.
Elliot continúa:
«O mira este, es más evidente»:
intitle:"index of" /backup
La pantalla muestra un directorio listado. El índice, los archivos, las fechas. Casi puedes sentir la gravedad del error. Es información pública; Google solo la ha descubierto primero.
Elliot apoya los codos en la mesa.
«Esto es Google Dorking. Nada ilegal. Buscamos lo que ya está expuesto. Como revisar los candados de tu propia casa. Y si encuentras una ventana rota, la arreglas antes de que otro la vea».
Darlene mira al techo. «La gente piensa que la seguridad es un bunker. Pero casi siempre es una persiana mal echada».
Los dos siguen navegando entre dorks como quien pasea entre sombras familiares. No hay urgencia, solo una especie de calma lúcida: la fase previa a cualquier intrusión ética, el territorio gris donde la información pública se mezcla con la negligencia.
Elliot concluye, casi en un susurro: «El buscador es el confidente más indiscreto de internet. Si le preguntas bien, te lo cuenta todo».
Buscadores alternativos y meta-buscadores
Cuando Google te cierra puertas, otros motores silenciosos dejan ventanas abiertas. No son magia negra; simplemente indexan distinto.
DuckDuckGo – Respeta privacidad y deja ver cosas que Google a veces filtra.
Shodan – El “Google del IoT”: cámaras, routers, PLCs, servidores expuestos. – Ideal para investigación forense o ética.
Censys – Similar a Shodan pero con enfoque más académico. – Perfecto para investigaciones de superficie de ataque.
Bing + Yandex – Indexan directorios de manera más permisiva en algunos casos.
Herramientas que automatizan Google Dorks (con cabeza)
No siempre quieres escribir cien consultas a mano. Estas herramientas generan, prueban y organizan dorks.
GHDB – Google Hacking Database (Exploit-DB) – La biblia. Miles de dorks clasificados por categorías (login pages, archivos sensibles, cámaras…). – La referencia imprescindible.
DorkSearch / DorkTester – Pequeñas herramientas web para probar dorks rápidamente. – Útiles para investigaciones rápidas sin automatizar demasiado.
Dork-Scanner (Python) – Frameworks que lanzan series de dorks y analizan respuestas. – Exigen ética e IP propia porque Google puede bloquearte.
Katana + Nuclei (ProjectDiscovery) – No son dorks, pero se llevan muy bien con ellos. – Puedes sacar URLs con Katana y luego comprobar hallazgos con Nuclei.
Extensiones de navegador
No subestimes las pequeñas utilidades de un clic.
Google Search Operators Helper – Te rellena operadores avanzados.
Search Diggity (BishopFox) – Conjunto de herramientas de OSINT con módulos de dorking seguro. – Muy usado en auditorías.
Herramientas OSINT que complementan Google Dorks
Porque un dork es solo un portal: después debes investigar.
theHarvester – Extrae correos, dominios, hosts desde motores de búsqueda. – Combinación perfecta con filetype:xls, pdf, txt…
FOCA – Analiza metadatos de documentos encontrados con dorks. – Joyas ocultas en PDFs y Word.
SpiderFoot – Rastrea información relacionada con dominios, subdominios y filtraciones.
Amass – Recon de subdominios. – Combinado con site: y inurl: puedes descubrir puertas laterales.
Herramientas forenses relacionadas
Cuando los dorks son parte de una investigación forense, estos compañeros hacen el resto:
Wayback Machine (Archive.org) – Para ver versiones antiguas de páginas descubiertas con dorks. – Oro puro cuando el contenido ha sido borrado.
Exiftool – Para explorar metadatos de imágenes encontradas.
Binwalk – Si encuentras firmware expuesto con un dork (sí, pasa), esta herramienta lo destripa.





![Practica [OSINT]- SEÑALES DE VIDA (O ALGO PEOR) EN LA RED](https://laaventuradeaprender.com/wp-content/uploads/2025/12/1f54e2931cc4aadf02b212bde85114a8.png)