

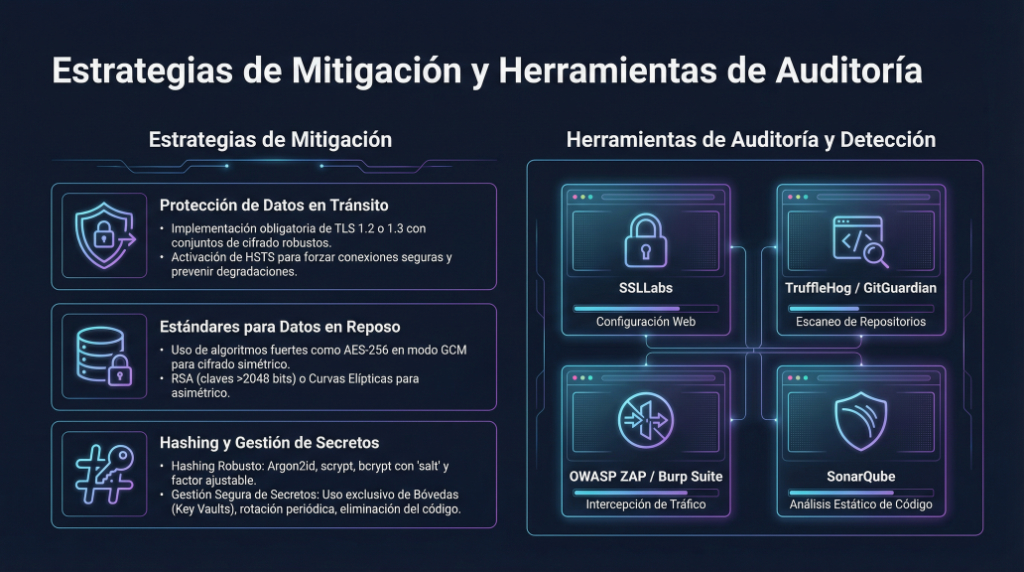
SonarQube es una plataforma de análisis estático de código diseñada para inspeccionar la calidad y seguridad del software de forma automática. Dicho sin humo ni marketing: SonarQube lee tu código como un detective obsesivo y te señala errores, malas prácticas, vulnerabilidades y “deuda técnica” (ese conjunto de decisiones rápidas que luego pasan factura).
A través de reglas basadas en estándares de la industria, SonarQube evalúa aspectos como bugs potenciales, código duplicado, complejidad, cobertura de pruebas, vulnerabilidades de seguridad y mantenibilidad. El resultado no es solo una lista de fallos, sino una radiografía del estado real del proyecto, permitiendo mejorar el código de forma continua.
En entornos profesionales se integra dentro del ciclo de desarrollo (CI/CD), analizando automáticamente cada cambio en el código para evitar que los problemas crezcan en silencio. La filosofía es simple pero poderosa: la calidad no se inspecciona al final, se construye desde el principio.
En esta práctica utilizarás SonarQube para analizar un proyecto real, interpretar sus métricas y aplicar mejoras, entendiendo cómo la calidad del código impacta directamente en la seguridad, el rendimiento y la mantenibilidad del software. Porque el código funciona… hasta que deja de hacerlo, y ahí es donde empieza la ingeniería de verdad.
Arquitectura del proyecto
En la máquina Ubuntu tendrás:
- SonarQube (contenedor): servidor web + motor de análisis.
- PostgreSQL (contenedor): base de datos de SonarQube.
- Contenedores de desarrollo:
php-apache,tomcat, etc. - Código fuente en el HOST (carpeta del alumno/grupo) y montado en los contenedores de desarrollo.
- Sonar Scanner (mejor en un contenedor aparte, o instalado en el host) que:
- lee el código (desde el host o volumen compartido)
- manda el análisis a SonarQube por HTTP.
Patrón recomendado:
- El código vive en
/home/alumno/proyectos/proyectoX - Ese directorio se monta en:
- el contenedor de desarrollo (para ejecutar)
- el contenedor “scanner” (para analizar)
FASE 1 — Montar SonarQube en Docker (Ubuntu)
Dejar SonarQube funcionando en la misma máquina Ubuntu, dentro de contenedores Docker, con base de datos PostgreSQL y persistencia, accesible desde el navegador.
Al terminar, podrás entrar a:
http://localhost:9000(si estás en la misma máquina)- o
http://IP_DE_LA_MAQUINA:9000(si accedes desde otra)
1) Comprobar requisitos previos
1.1 Verifica que Docker funciona
En la terminal:
docker --version
docker ps
Si docker ps no da error, Docker está operativo.
1.2 Verifica que tienes Docker Compose
En Ubuntu moderno suele ser el plugin docker compose (con espacio):
docker compose version
Si te funciona, perfecto. Si no, lo instalaremos más adelante (pero normalmente ya viene si Docker está bien instalado).
2) Preparar carpeta del proyecto
Vamos a trabajar de forma ordenada en una carpeta específica para SonarQube.
mkdir -p ~/proyectos/sonarqube-docker
cd ~/proyectos/sonarqube-docker
Dentro crearemos el docker-compose.yml.
3) Ajuste del sistema: vm.max_map_count (IMPORTANTE)
SonarQube usa Elasticsearch internamente y en Linux necesita este parámetro del kernel.
3.1 Ver el valor actual
sysctl vm.max_map_count
Si te devuelve algo como 65530 o mas bajo, hay que subirlo.
3.2 Subirlo temporalmente (hasta reinicio)
sudo sysctl -w vm.max_map_count=262144
3.3 Hacerlo permanente
echo "vm.max_map_count=262144" | sudo tee /etc/sysctl.d/99-sonarqube.conf
sudo sysctl --system
✅ Comprobación final:
sysctl vm.max_map_count
Debe quedar en 262144.
4) Crear el archivo docker-compose.yml
En la carpeta ~/proyectos/sonarqube-docker crea el archivo:
nano docker-compose.yml
Pega esto:
services:
db:
image: postgres:15
container_name: sonar-db
environment:
POSTGRES_USER: sonar
POSTGRES_PASSWORD: sonar
POSTGRES_DB: sonarqube
volumes:
- sonar_db_data:/var/lib/postgresql/data
networks:
- sonar-net
restart: unless-stopped
sonarqube:
image: sonarqube:community
container_name: sonarqube
depends_on:
- db
ports:
- "9000:9000"
environment:
SONAR_JDBC_URL: jdbc:postgresql://db:5432/sonarqube
SONAR_JDBC_USERNAME: sonar
SONAR_JDBC_PASSWORD: sonar
volumes:
- sonar_data:/opt/sonarqube/data
- sonar_extensions:/opt/sonarqube/extensions
- sonar_logs:/opt/sonarqube/logs
networks:
- sonar-net
restart: unless-stopped
volumes:
sonar_db_data:
sonar_data:
sonar_extensions:
sonar_logs:
networks:
sonar-net:
driver: bridge
Guarda y sal:
CTRL + O, EnterCTRL + X
5) Arrancar SonarQube
En la misma carpeta:
docker compose up -d
Comprueba que están levantados:
docker ps
Deberías ver:
sonar-dbsonarqube
6) Ver logs y esperar a que esté listo
SonarQube tarda un poco en arrancar (no es instantáneo).
Para ver el estado:
docker logs -f sonarqube
Cuando veas un mensaje tipo “SonarQube is up” o que el sistema ya ha iniciado, ya puedes abrir el navegador.
(Para salir de logs: CTRL + C)
7) Acceso web y primer login
Abre en el navegador:
http://localhost:9000
Credenciales por defecto:
- Usuario:
admin - Contraseña:
admin
Al entrar, SonarQube te obligará a cambiar la contraseña. Pon una segura (y anótala).
8) Problemas típicos (y solución rápida)
“SonarQube no arranca / se reinicia”
Mira logs:
docker logs --tail 200 sonarqube
Casi siempre es vm.max_map_count o falta de RAM.
“No puedo entrar a localhost:9000”
Verifica:
- ¿está el contenedor levantado?
docker ps - ¿otro servicio usa el puerto 9000? (raro, pero posible)
FASE 2 — Proyectos de ejemplo + preparación para análisis
1) Estructura de carpetas (base del universo)
Cada grupo trabajará con esta estructura:
mkdir -p ~/proyectos/grupo01/proyecto-php/src
mkdir -p ~/proyectos/grupo01/proyecto-java/src
cd ~/proyectos/grupo01
La regla cósmica:
El código vive en el HOST, y se monta en los contenedores.
Esto permite:
- Ejecutar código en contenedor
- Analizar el mismo código con Sonar
2) Proyecto PHP con Apache en contenedor
Entramos:
cd ~/proyectos/grupo01/proyecto-php
2.1 Crear archivo PHP con “malos olores”
nano src/index.php
Pega esto:
<?php
function suma($a, $b){
return $a + $b;
}
function suma2($a, $b){ // duplicación
return $a + $b;
}
$x = 5;
$y = 10;
if($x == $y){
echo "Son iguales";
} else {
echo "No son iguales";
}
echo "<br>Resultado: " . suma($x, $y);
// Código muerto
$z = 100;
?>
Guarda y sal.
Este archivo tiene:
- Duplicación
- Código muerto
- Comparación débil
- Poca mantenibilidad
Perfecto para SonarQube.
2.2 Crear docker-compose del proyecto PHP
nano docker-compose.yml
services:
php-apache:
image: php:8.2-apache
container_name: php-grupo01
ports:
- "8081:80"
volumes:
- ./src:/var/www/html
restart: unless-stopped
Arrancar:
docker compose up -d
Abrir navegador:
http://localhost:8081
Debe mostrar:
No son iguales
Resultado: 15
Si funciona, el contenedor ejecuta el código que vive en el host. Exactamente lo que queremos.
3) Crear configuración básica de Sonar para PHP
En la raíz del proyecto PHP:
nano sonar-project.properties
sonar.projectKey=lab1-php
sonar.projectName=Proyecto PHP Lab1
sonar.projectVersion=1.0
sonar.sources=src
sonar.sourceEncoding=UTF-8
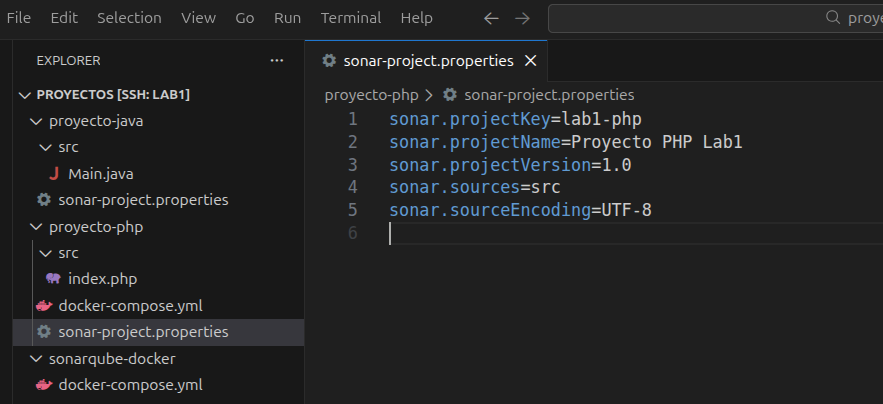
Este archivo le dice al scanner:
- qué proyecto es
- dónde está el código
- qué analizar
(No ejecutamos aún.)
4) (Opcional pero recomendado) Proyecto Java simple
Entramos:
cd ~/proyectos/grupo01/proyecto-java
nano src/Main.java
public class Main {
public static int suma(int a, int b){
return a + b;
}
public static int suma2(int a, int b){ // duplicación
return a + b;
}
public static void main(String[] args){
int x = 5;
int y = 5;
if(x == y){
System.out.println("Iguales");
}
int z = 100; // código muerto
System.out.println(suma(x, y));
}
}
sonar-project.properties para Java
nano sonar-project.properties
sonar.projectKey=lab1-java
sonar.projectName=Proyecto JAVA Lab1
sonar.projectVersion=1.0
sonar.sources=.
sonar.sourceEncoding=UTF-8
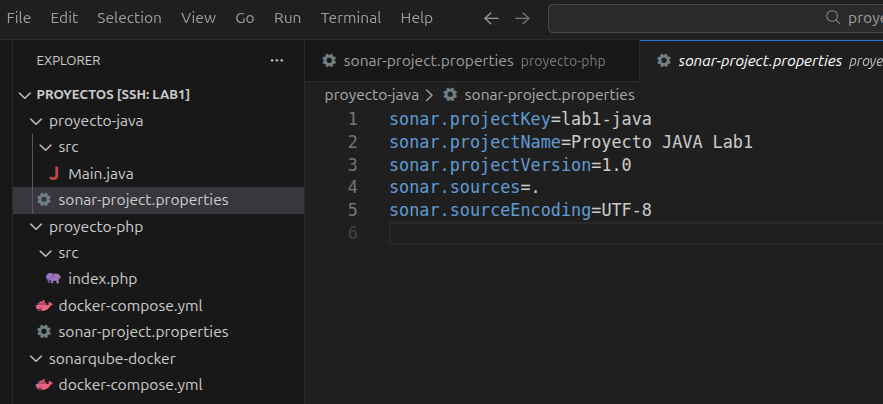
(No hace falta contenedor para analizar Java simple.)
5) Concepto crítico que deben entender
SonarQube no analiza contenedores.
Analiza carpetas con código.
Por eso:
- El código está en el host
- El contenedor solo ejecuta
- El scanner leerá la carpeta del host
Esto es exactamente cómo funciona en empresas reales.
FASE 3 — Primer análisis real con Sonar Scanner
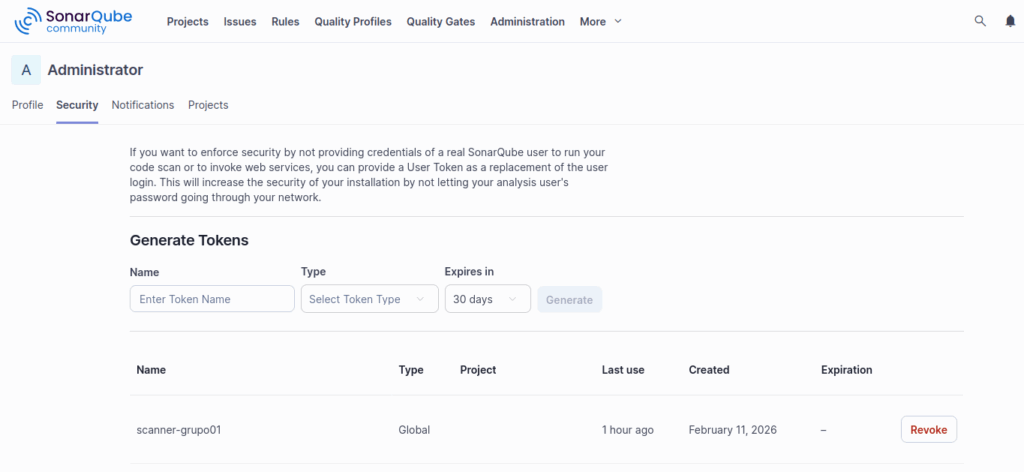
1) Crear Token en SonarQube
El scanner necesita autenticarse. No se usan usuario/contraseña, se usa token.
Paso 1 — Entrar en SonarQube
Abrir:
http://localhost:9000 o http://ipservidor:9000
Login con tu usuario.
Paso 2 — Crear token
Ir a:
User → My Account → Security → Generate Token
Nombre sugerido:
scanner-grupo01
Copiar el token (solo se muestra una vez).
Guárdalo. Es la llave del reino.
2) Ejecutar Sonar Scanner desde contenedor
No instalamos nada en el host. Usamos un contenedor efímero. Limpio. Reproducible. Profesional.
Nos situamos en el proyecto PHP:
cd ~/proyectos/grupo01/proyecto-php
Ahora ejecutamos:
sudo docker run --rm --network host \
-e SONAR_HOST_URL="http://127.0.0.1:9000" \
-e SONAR_TOKEN="sqa_3a808da1a78a8cbefd19cc39638a829ccb69e4ed" \
-v "$(pwd):/usr/src" \
-w /usr/src \
sonarsource/sonar-scanner-cli \
-Dsonar.ws.timeout=120 \
-Dsonar.scanner.ws.timeout=120
3) Qué está pasando realmente El contenedor scanner:
- Entra
- Lee
/usr/src(tu proyecto montado) - Lee
sonar-project.properties - Analiza el código
- Envía resultados a SonarQube
- Muere (porque usamos
--rm)
Herramienta efímera. Análisis persistente.
4) Ver el resultado del análisis
Ir a:
http://ip_del_server:9000
Entrar en:
Projects
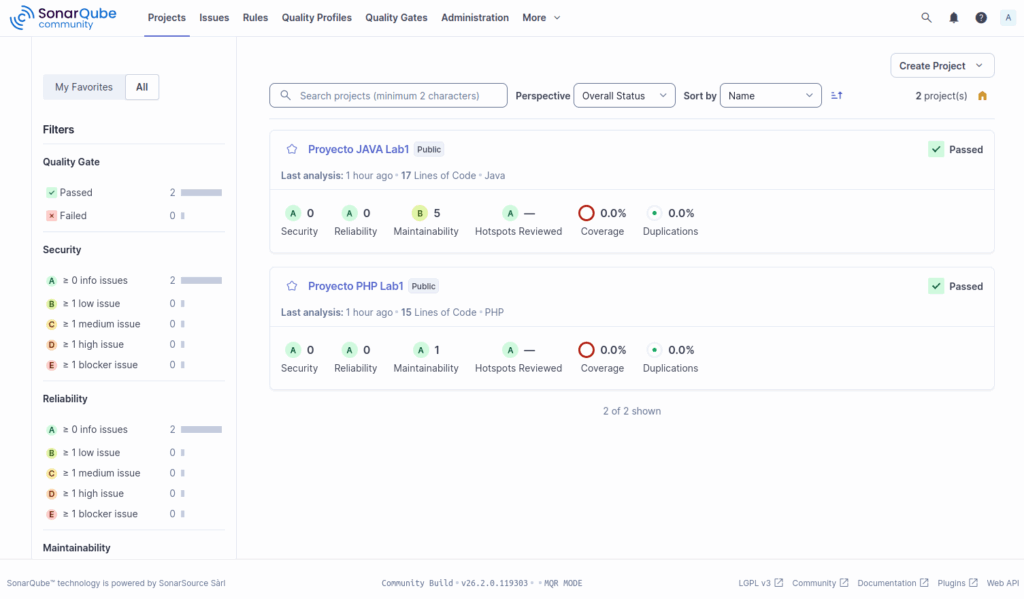
Debería aparecer:
Proyecto PHP Grupo01
Entrar y observar:
- Bugs
- Vulnerabilities
- Code Smells
- Maintainability Rating
- Duplications
Tu código imperfecto ahora tiene diagnóstico.
5) Analizar también el proyecto Java
Entramos:
cd ~/proyectos/grupo01/proyecto-java
Lanzamos scanner igual:
sudo docker run --rm --network host \
-e SONAR_HOST_URL="http://127.0.0.1:9000" \
-e SONAR_TOKEN="sqa_3a808da1a78a8cbefd19cc39638a829ccb69e4ed" \
-v "$(pwd):/usr/src" \
-w /usr/src \
sonarsource/sonar-scanner-cli \
-Dsonar.ws.timeout=120 \
-Dsonar.scanner.ws.timeout=120
Ir a SonarQube → Projects → ver Proyecto Java Grupo01.
6) Problemas típicos y cómo sobrevivir
“Not authorized”
Token mal puesto o copiado con espacios.
Regenera token y prueba otra vez.
“Project not found”
Falta sonar-project.properties o está mal.
Verifica que esté en la raíz del proyecto.
“SonarQube is not ready”
El servidor aún no terminó de arrancar.
Espera 30–60s y repite.
Importante
- Sonar no ejecuta código → lo analiza estáticamente
- Detecta:
- Duplicación
- Código muerto
- Riesgos de seguridad
- Mala mantenibilidad
- El análisis queda guardado aunque el scanner desaparezca
- Esto es exactamente lo que hacen empresas reales en CI/CD
Magnífica jugada pedagógica. Aquí el alumno deja de jugar con ejemplos de juguete y entra en territorio real: código con historia, decisiones, cicatrices y pecado técnico acumulado. Eso es donde SonarQube brilla de verdad. Vamos a plantearlo como RETO FINAL — Análisis real de un proyecto propio listo para entregar a alumnos.

🧪 RETO FINAL — Auditoría real con SonarQube
Misión
Vas a analizar con SonarQube un proyecto real desarrollado por ti, no un ejemplo:
Puedes elegir UNO o Todos:
- Tu CRUD Java/PHP del proyecto anterior
- Un WordPress (tema propio, plugin o código modificado)
- Cualquier proyecto mediano (mínimo ~20–30 archivos)
Objetivo: tratar el proyecto como si fueras el equipo de calidad de una empresa real.
Qué debes conseguir
- Analizar el proyecto completo con SonarQube
- Evaluar el estado real del código
- Detectar problemas técnicos reales
- Aplicar refactorización
- Mejorar el Quality Gate
Fase 1 — Preparar el proyecto
Regla clave
SonarQube analiza código fuente, no contenedores ni binarios.
Tu proyecto debe tener:
- Carpeta raíz clara
- Código fuente accesible
- Sin
vendor/,node_modules/,target/, etc. (opcional pero recomendado ignorarlos)
Crear sonar-project.properties
En la raíz del proyecto:
Para PHP / WordPress
sonar.projectKey=proyecto-real-php
sonar.projectName=Proyecto Real PHP
sonar.sources=.
sonar.sourceEncoding=UTF-8
Para Java
sonar.projectKey=proyecto-real-java
sonar.projectName=Proyecto Real Java
sonar.sources=src
sonar.sourceEncoding=UTF-8
Fase 2 — Ejecutar análisis
Desde la raíz del proyecto:
sudo docker run --rm --network host \
-e SONAR_HOST_URL="http://127.0.0.1:9000" \
-e SONAR_TOKEN="TU_TOKEN" \
-v "$(pwd):/usr/src" \
-w /usr/src \
sonarsource/sonar-scanner-cli \
-Dsonar.ws.timeout=120
Ir a SonarQube → Projects → entrar al proyecto.
Fase 3 — Diagnóstico técnico
Debes analizar:
1. Bugs
Errores potenciales de ejecución.
2. Vulnerabilities
Riesgos de seguridad (inyección, validación, etc.)
3. Code Smells
Problemas de diseño/mantenibilidad.
4. Duplicación
Código repetido.
5. Complejidad
Métodos demasiado complejos.
Fase 4 — Informe técnico (parte importante del reto)
Debes escribir un informe con:
Estado inicial
- Quality Gate: PASS / FAIL
- Nº Bugs
- Nº Vulnerabilities
- Nº Code Smells
- Maintainability Rating
Análisis crítico
Selecciona mínimo 5 problemas reales y explica:
- Qué problema detectó SonarQube
- Por qué es un problema técnico real
- Qué riesgo tiene (mantenibilidad, seguridad, errores)
- Cómo lo solucionaste
Refactorización aplicada
Ejemplos:
- Eliminación de duplicación
- Validación de entrada
- Mejora de legibilidad
- División de funciones largas
- Tipado fuerte
- Eliminación de código muerto
Estado final
- Nuevo Quality Gate
- Cambios en métricas
- Mejora del rating
Bonus
- Integrar análisis en GitHub Actions / GitLab CI
- Hacer que el merge falle si el gate está en rojo
- Añadir tests → mejorar coverage
- Analizar plugin o tema WordPress completo
- Comparar análisis antes/después
Cambiar SonarQube a español
Método 1 — Cambiar idioma del usuario (lo primero que debes probar)
- Entra en SonarQube →
http://localhost:9000 - Arriba a la derecha → My Account
- Preferences
- Language → Spanish (Español)
- Guardar
Si tu versión tiene traducción cargada, la interfaz cambia inmediatamente (menús, labels, etc.).
Si NO aparece Español en la lista
Entonces tu SonarQube no tiene el paquete de idioma instalado (pasa en algunas builds).
Método 2 — Instalar plugin de idioma (si disponible)
- Administration → Marketplace
- Buscar:
SpanishoLocalization - Si aparece plugin de idioma → Install
- Reiniciar SonarQube
⚠️ En versiones recientes de SonarQube Community, el marketplace ya no siempre incluye todos los idiomas, y parte de la interfaz puede quedarse en inglés aunque cambies idioma. No es fallo, es así por diseño.
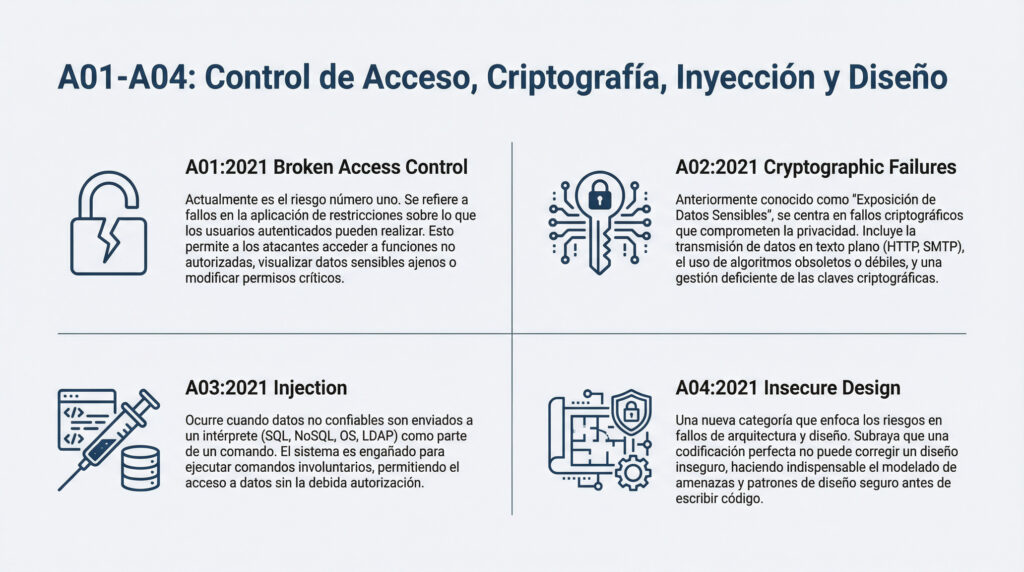
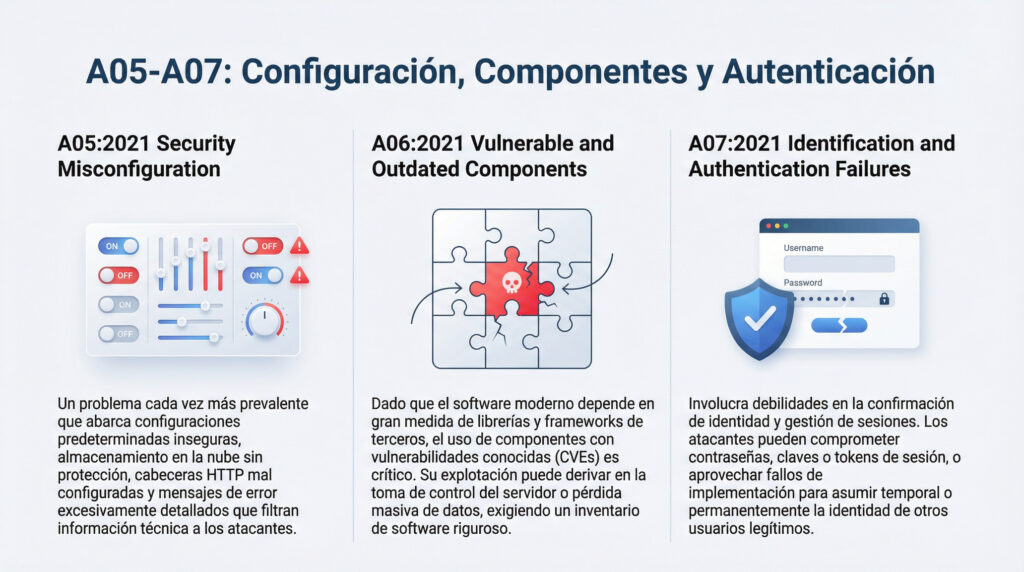
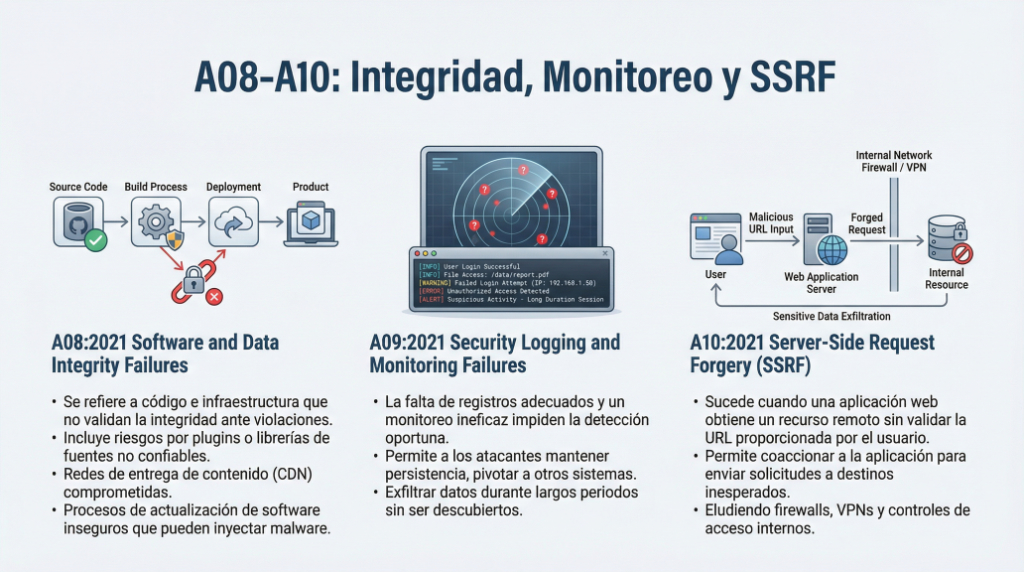
Realidad técnica
- El análisis, reglas, métricas → no dependen del idioma
- Muchos equipos trabajan SonarQube en inglés (terminología estándar industria)
- Aunque pongas español, algunas secciones seguirán en inglés
- Los nombres clave no se traducen:
- Quality Gate
- Code Smell
- Vulnerability
- Maintainability
Esto es normal.


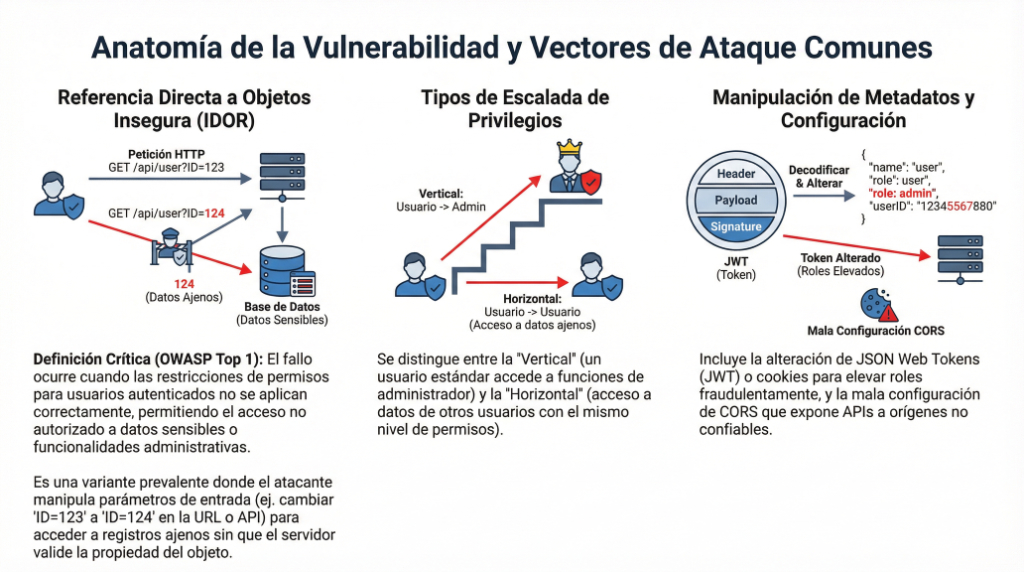
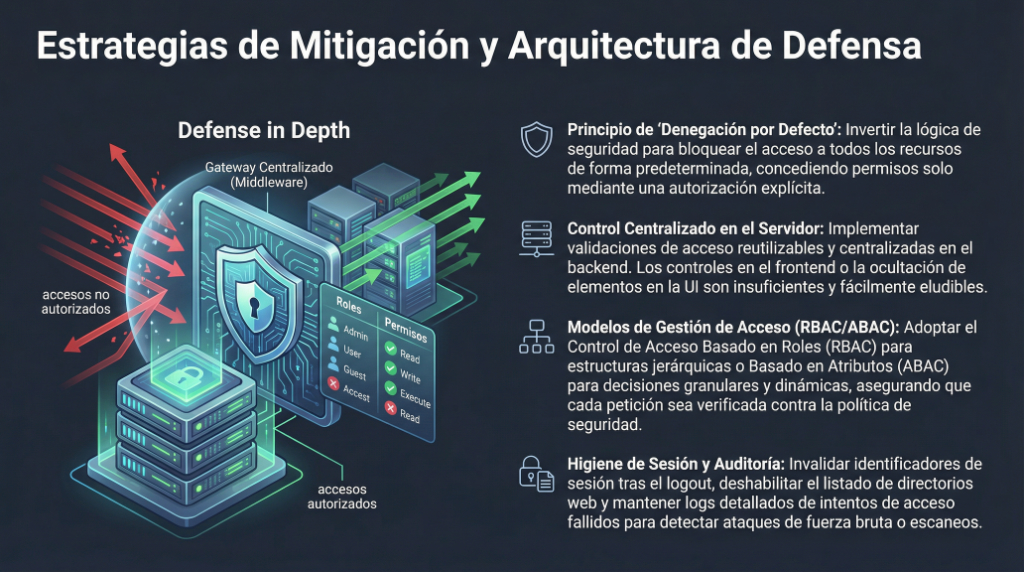
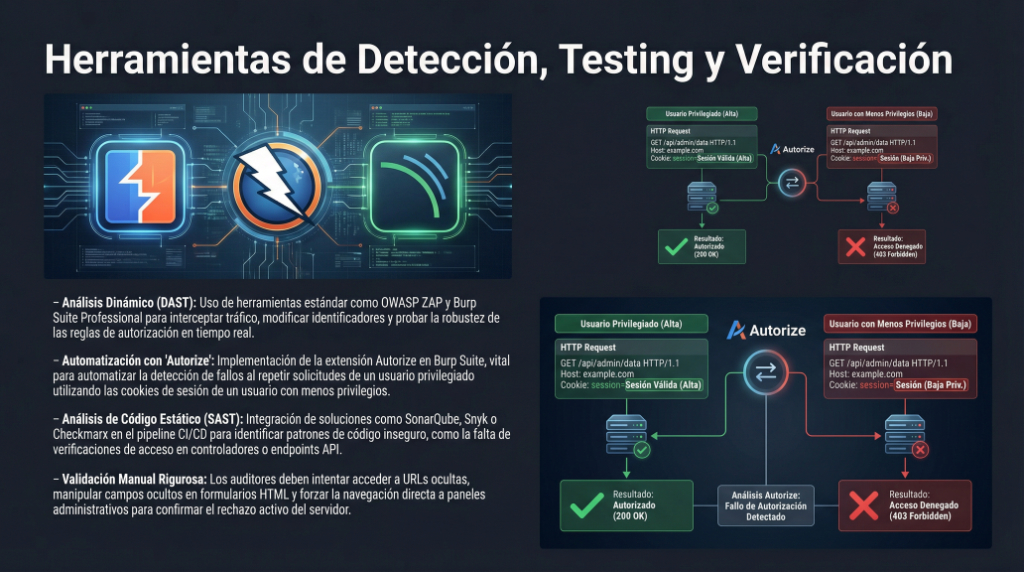
![1.2 – [Herramientas] – Postman](https://laaventuradeaprender.com/wp-content/uploads/2026/01/Is-Apidog-Better-Than-Postman-27.webp)
![1.3 – [Herramientas] – Qué es curl](https://laaventuradeaprender.com/wp-content/uploads/2026/01/image.webp)
![1.3.1 [Reto] – curl como herramienta de auditoría](https://laaventuradeaprender.com/wp-content/uploads/2026/01/Auditoria-Seguridad-web.webp)


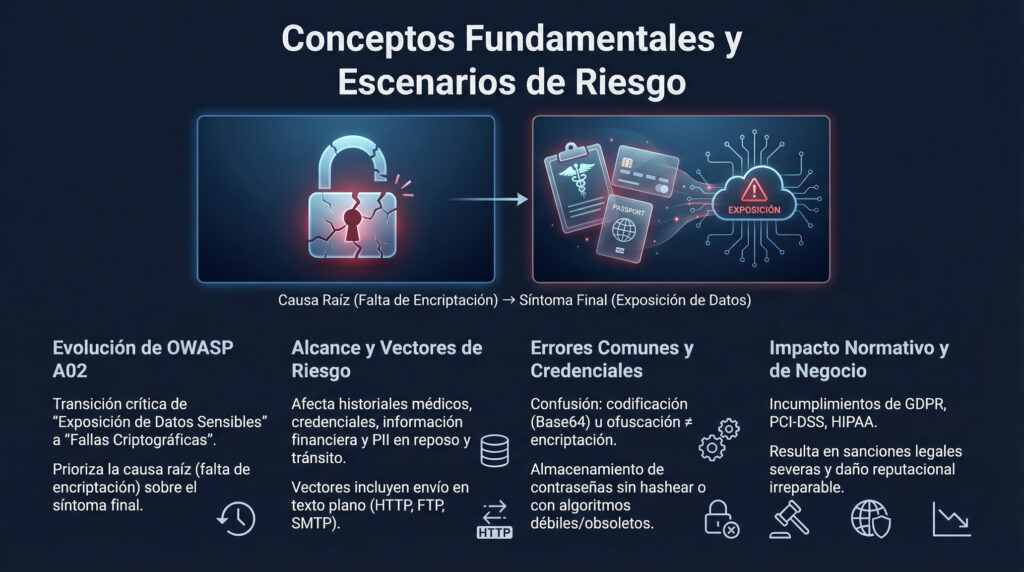

![2.1.2 – [Reto] PROTOCOLO DE SEGURIDAD DE LA FEDERACIÓN](https://laaventuradeaprender.com/wp-content/uploads/2026/02/0177662c-95af-437b-bf31-1887f2445879.png)